skwdro.distributions package
Submodules
skwdro.distributions.dirac_distribution module
- class skwdro.distributions.dirac_distribution.Dirac(loc: Tensor, n_batch_dims: int = 0, validate_args: bool | None = None)[source]
Bases:
ExponentialFamily- property arg_constraints: Dict[str, Constraint]
Returns a dictionary from argument names to
Constraintobjects that should be satisfied by each argument of this distribution. Args that are not tensors need not appear in this dict.
- entropy() Tensor[source]
Method to compute the entropy using Bregman divergence of the log normalizer.
- enumerate_support(expand: bool = True) Tensor[source]
Returns tensor containing all values supported by a discrete distribution. The result will enumerate over dimension 0, so the shape of the result will be (cardinality,) + batch_shape + event_shape (where event_shape = () for univariate distributions).
Note that this enumerates over all batched tensors in lock-step [[0, 0], [1, 1], …]. With expand=False, enumeration happens along dim 0, but with the remaining batch dimensions being singleton dimensions, [[0], [1], ...
To iterate over the full Cartesian product use itertools.product(m.enumerate_support()).
- Args:
- expand (bool): whether to expand the support over the
batch dims to match the distribution’s batch_shape.
- Returns:
Tensor iterating over dimension 0.
- expand(batch_shape: Size | List[int] | Tuple[int, ...], _instance=None)[source]
Returns a new distribution instance (or populates an existing instance provided by a derived class) with batch dimensions expanded to batch_shape. This method calls
expandon the distribution’s parameters. As such, this does not allocate new memory for the expanded distribution instance. Additionally, this does not repeat any args checking or parameter broadcasting in __init__.py, when an instance is first created.- Args:
batch_shape (torch.Size): the desired expanded size. _instance: new instance provided by subclasses that
need to override .expand.
- Returns:
New distribution instance with batch dimensions expanded to batch_size.
- has_rsample = True
- log_prob(value: Tensor) Tensor[source]
Returns the log of the probability density/mass function evaluated at value.
- Args:
value (Tensor):
- property mean: Tensor
Returns the mean of the distribution.
- property mode: Tensor
Returns the mode of the distribution.
- perplexity() Tensor[source]
Returns perplexity of distribution, batched over batch_shape.
- Returns:
Tensor of shape batch_shape.
- rsample(sample_shape: Size | List[int] | Tuple[int, ...] = ()) Tensor[source]
Generates a sample_shape shaped reparameterized sample or sample_shape shaped batch of reparameterized samples if the distribution parameters are batched.
- property support: Constraint | None
Returns a
Constraintobject representing this distribution’s support.
- property variance: Tensor
Returns the variance of the distribution.
Module contents
- class skwdro.distributions.AbsTransform(cache_size=0)[source]
Bases:
TransformTransform via the mapping
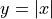 .
.- codomain: Constraint = GreaterThan(lower_bound=0.0)
- domain: Constraint = Real()
- class skwdro.distributions.AffineTransform(loc, scale, event_dim=0, cache_size=0)[source]
Bases:
TransformTransform via the pointwise affine mapping
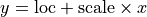 .
.- Args:
loc (Tensor or float): Location parameter. scale (Tensor or float): Scale parameter. event_dim (int): Optional size of event_shape. This should be zero
for univariate random variables, 1 for distributions over vectors, 2 for distributions over matrices, etc.
- bijective = True
- property codomain
- property domain
- property event_dim
- forward_shape(shape)[source]
Infers the shape of the forward computation, given the input shape. Defaults to preserving shape.
- inverse_shape(shape)[source]
Infers the shapes of the inverse computation, given the output shape. Defaults to preserving shape.
- log_abs_det_jacobian(x, y)[source]
Computes the log det jacobian log |dy/dx| given input and output.
- property sign
Returns the sign of the determinant of the Jacobian, if applicable. In general this only makes sense for bijective transforms.
- class skwdro.distributions.Bernoulli(probs=None, logits=None, validate_args=None)[source]
Bases:
ExponentialFamilyCreates a Bernoulli distribution parameterized by
probsorlogits(but not both).Samples are binary (0 or 1). They take the value 1 with probability p and 0 with probability 1 - p.
Example:
>>> # xdoctest: +IGNORE_WANT("non-deterministic") >>> m = Bernoulli(torch.tensor([0.3])) >>> m.sample() # 30% chance 1; 70% chance 0 tensor([ 0.])
- Args:
probs (Number, Tensor): the probability of sampling 1 logits (Number, Tensor): the log-odds of sampling 1
- arg_constraints = {'logits': Real(), 'probs': Interval(lower_bound=0.0, upper_bound=1.0)}
- enumerate_support(expand=True)[source]
Returns tensor containing all values supported by a discrete distribution. The result will enumerate over dimension 0, so the shape of the result will be (cardinality,) + batch_shape + event_shape (where event_shape = () for univariate distributions).
Note that this enumerates over all batched tensors in lock-step [[0, 0], [1, 1], …]. With expand=False, enumeration happens along dim 0, but with the remaining batch dimensions being singleton dimensions, [[0], [1], ...
To iterate over the full Cartesian product use itertools.product(m.enumerate_support()).
- Args:
- expand (bool): whether to expand the support over the
batch dims to match the distribution’s batch_shape.
- Returns:
Tensor iterating over dimension 0.
- expand(batch_shape, _instance=None)[source]
Returns a new distribution instance (or populates an existing instance provided by a derived class) with batch dimensions expanded to batch_shape. This method calls
expandon the distribution’s parameters. As such, this does not allocate new memory for the expanded distribution instance. Additionally, this does not repeat any args checking or parameter broadcasting in __init__.py, when an instance is first created.- Args:
batch_shape (torch.Size): the desired expanded size. _instance: new instance provided by subclasses that
need to override .expand.
- Returns:
New distribution instance with batch dimensions expanded to batch_size.
- has_enumerate_support = True
- log_prob(value)[source]
Returns the log of the probability density/mass function evaluated at value.
- Args:
value (Tensor):
- property logits
- property mean
Returns the mean of the distribution.
- property mode
Returns the mode of the distribution.
- property param_shape
- property probs
- sample(sample_shape=())[source]
Generates a sample_shape shaped sample or sample_shape shaped batch of samples if the distribution parameters are batched.
- support = Boolean()
- property variance
Returns the variance of the distribution.
- class skwdro.distributions.Beta(concentration1, concentration0, validate_args=None)[source]
Bases:
ExponentialFamilyBeta distribution parameterized by
concentration1andconcentration0.Example:
>>> # xdoctest: +IGNORE_WANT("non-deterministic") >>> m = Beta(torch.tensor([0.5]), torch.tensor([0.5])) >>> m.sample() # Beta distributed with concentration concentration1 and concentration0 tensor([ 0.1046])
- Args:
- concentration1 (float or Tensor): 1st concentration parameter of the distribution
(often referred to as alpha)
- concentration0 (float or Tensor): 2nd concentration parameter of the distribution
(often referred to as beta)
- arg_constraints = {'concentration0': GreaterThan(lower_bound=0.0), 'concentration1': GreaterThan(lower_bound=0.0)}
- property concentration0
- property concentration1
- expand(batch_shape, _instance=None)[source]
Returns a new distribution instance (or populates an existing instance provided by a derived class) with batch dimensions expanded to batch_shape. This method calls
expandon the distribution’s parameters. As such, this does not allocate new memory for the expanded distribution instance. Additionally, this does not repeat any args checking or parameter broadcasting in __init__.py, when an instance is first created.- Args:
batch_shape (torch.Size): the desired expanded size. _instance: new instance provided by subclasses that
need to override .expand.
- Returns:
New distribution instance with batch dimensions expanded to batch_size.
- has_rsample = True
- log_prob(value)[source]
Returns the log of the probability density/mass function evaluated at value.
- Args:
value (Tensor):
- property mean
Returns the mean of the distribution.
- property mode
Returns the mode of the distribution.
- rsample(sample_shape: Size | List[int] | Tuple[int, ...] = ()) Tensor[source]
Generates a sample_shape shaped reparameterized sample or sample_shape shaped batch of reparameterized samples if the distribution parameters are batched.
- support = Interval(lower_bound=0.0, upper_bound=1.0)
- property variance
Returns the variance of the distribution.
- class skwdro.distributions.Binomial(total_count=1, probs=None, logits=None, validate_args=None)[source]
Bases:
DistributionCreates a Binomial distribution parameterized by
total_countand eitherprobsorlogits(but not both).total_countmust be broadcastable withprobs/logits.Example:
>>> # xdoctest: +IGNORE_WANT("non-deterministic") >>> m = Binomial(100, torch.tensor([0 , .2, .8, 1])) >>> x = m.sample() tensor([ 0., 22., 71., 100.]) >>> m = Binomial(torch.tensor([[5.], [10.]]), torch.tensor([0.5, 0.8])) >>> x = m.sample() tensor([[ 4., 5.], [ 7., 6.]])
- Args:
total_count (int or Tensor): number of Bernoulli trials probs (Tensor): Event probabilities logits (Tensor): Event log-odds
- arg_constraints = {'logits': Real(), 'probs': Interval(lower_bound=0.0, upper_bound=1.0), 'total_count': IntegerGreaterThan(lower_bound=0)}
- entropy()[source]
Returns entropy of distribution, batched over batch_shape.
- Returns:
Tensor of shape batch_shape.
- enumerate_support(expand=True)[source]
Returns tensor containing all values supported by a discrete distribution. The result will enumerate over dimension 0, so the shape of the result will be (cardinality,) + batch_shape + event_shape (where event_shape = () for univariate distributions).
Note that this enumerates over all batched tensors in lock-step [[0, 0], [1, 1], …]. With expand=False, enumeration happens along dim 0, but with the remaining batch dimensions being singleton dimensions, [[0], [1], ...
To iterate over the full Cartesian product use itertools.product(m.enumerate_support()).
- Args:
- expand (bool): whether to expand the support over the
batch dims to match the distribution’s batch_shape.
- Returns:
Tensor iterating over dimension 0.
- expand(batch_shape, _instance=None)[source]
Returns a new distribution instance (or populates an existing instance provided by a derived class) with batch dimensions expanded to batch_shape. This method calls
expandon the distribution’s parameters. As such, this does not allocate new memory for the expanded distribution instance. Additionally, this does not repeat any args checking or parameter broadcasting in __init__.py, when an instance is first created.- Args:
batch_shape (torch.Size): the desired expanded size. _instance: new instance provided by subclasses that
need to override .expand.
- Returns:
New distribution instance with batch dimensions expanded to batch_size.
- has_enumerate_support = True
- log_prob(value)[source]
Returns the log of the probability density/mass function evaluated at value.
- Args:
value (Tensor):
- property logits
- property mean
Returns the mean of the distribution.
- property mode
Returns the mode of the distribution.
- property param_shape
- property probs
- sample(sample_shape=())[source]
Generates a sample_shape shaped sample or sample_shape shaped batch of samples if the distribution parameters are batched.
- property support
Returns a
Constraintobject representing this distribution’s support.
- property variance
Returns the variance of the distribution.
- class skwdro.distributions.CatTransform(tseq, dim=0, lengths=None, cache_size=0)[source]
Bases:
TransformTransform functor that applies a sequence of transforms tseq component-wise to each submatrix at dim, of length lengths[dim], in a way compatible with
torch.cat().Example:
x0 = torch.cat([torch.range(1, 10), torch.range(1, 10)], dim=0) x = torch.cat([x0, x0], dim=0) t0 = CatTransform([ExpTransform(), identity_transform], dim=0, lengths=[10, 10]) t = CatTransform([t0, t0], dim=0, lengths=[20, 20]) y = t(x)
- property bijective
bool(x) -> bool
Returns True when the argument x is true, False otherwise. The builtins True and False are the only two instances of the class bool. The class bool is a subclass of the class int, and cannot be subclassed.
- property codomain
- property domain
- property event_dim
- property length
- class skwdro.distributions.Categorical(probs=None, logits=None, validate_args=None)[source]
Bases:
DistributionCreates a categorical distribution parameterized by either
probsorlogits(but not both).Note
It is equivalent to the distribution that
torch.multinomial()samples from.Samples are integers from
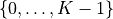 where K is
where K is probs.size(-1).If probs is 1-dimensional with length-K, each element is the relative probability of sampling the class at that index.
If probs is N-dimensional, the first N-1 dimensions are treated as a batch of relative probability vectors.
Note
The probs argument must be non-negative, finite and have a non-zero sum, and it will be normalized to sum to 1 along the last dimension.
probswill return this normalized value. The logits argument will be interpreted as unnormalized log probabilities and can therefore be any real number. It will likewise be normalized so that the resulting probabilities sum to 1 along the last dimension.logitswill return this normalized value.See also:
torch.multinomial()Example:
>>> # xdoctest: +IGNORE_WANT("non-deterministic") >>> m = Categorical(torch.tensor([ 0.25, 0.25, 0.25, 0.25 ])) >>> m.sample() # equal probability of 0, 1, 2, 3 tensor(3)
- Args:
probs (Tensor): event probabilities logits (Tensor): event log probabilities (unnormalized)
- arg_constraints = {'logits': IndependentConstraint(Real(), 1), 'probs': Simplex()}
- entropy()[source]
Returns entropy of distribution, batched over batch_shape.
- Returns:
Tensor of shape batch_shape.
- enumerate_support(expand=True)[source]
Returns tensor containing all values supported by a discrete distribution. The result will enumerate over dimension 0, so the shape of the result will be (cardinality,) + batch_shape + event_shape (where event_shape = () for univariate distributions).
Note that this enumerates over all batched tensors in lock-step [[0, 0], [1, 1], …]. With expand=False, enumeration happens along dim 0, but with the remaining batch dimensions being singleton dimensions, [[0], [1], ...
To iterate over the full Cartesian product use itertools.product(m.enumerate_support()).
- Args:
- expand (bool): whether to expand the support over the
batch dims to match the distribution’s batch_shape.
- Returns:
Tensor iterating over dimension 0.
- expand(batch_shape, _instance=None)[source]
Returns a new distribution instance (or populates an existing instance provided by a derived class) with batch dimensions expanded to batch_shape. This method calls
expandon the distribution’s parameters. As such, this does not allocate new memory for the expanded distribution instance. Additionally, this does not repeat any args checking or parameter broadcasting in __init__.py, when an instance is first created.- Args:
batch_shape (torch.Size): the desired expanded size. _instance: new instance provided by subclasses that
need to override .expand.
- Returns:
New distribution instance with batch dimensions expanded to batch_size.
- has_enumerate_support = True
- log_prob(value)[source]
Returns the log of the probability density/mass function evaluated at value.
- Args:
value (Tensor):
- property logits
- property mean
Returns the mean of the distribution.
- property mode
Returns the mode of the distribution.
- property param_shape
- property probs
- sample(sample_shape=())[source]
Generates a sample_shape shaped sample or sample_shape shaped batch of samples if the distribution parameters are batched.
- property support
Returns a
Constraintobject representing this distribution’s support.
- property variance
Returns the variance of the distribution.
- class skwdro.distributions.Cauchy(loc, scale, validate_args=None)[source]
Bases:
DistributionSamples from a Cauchy (Lorentz) distribution. The distribution of the ratio of independent normally distributed random variables with means 0 follows a Cauchy distribution.
Example:
>>> # xdoctest: +IGNORE_WANT("non-deterministic") >>> m = Cauchy(torch.tensor([0.0]), torch.tensor([1.0])) >>> m.sample() # sample from a Cauchy distribution with loc=0 and scale=1 tensor([ 2.3214])
- Args:
loc (float or Tensor): mode or median of the distribution. scale (float or Tensor): half width at half maximum.
- arg_constraints = {'loc': Real(), 'scale': GreaterThan(lower_bound=0.0)}
- cdf(value)[source]
Returns the cumulative density/mass function evaluated at value.
- Args:
value (Tensor):
- entropy()[source]
Returns entropy of distribution, batched over batch_shape.
- Returns:
Tensor of shape batch_shape.
- expand(batch_shape, _instance=None)[source]
Returns a new distribution instance (or populates an existing instance provided by a derived class) with batch dimensions expanded to batch_shape. This method calls
expandon the distribution’s parameters. As such, this does not allocate new memory for the expanded distribution instance. Additionally, this does not repeat any args checking or parameter broadcasting in __init__.py, when an instance is first created.- Args:
batch_shape (torch.Size): the desired expanded size. _instance: new instance provided by subclasses that
need to override .expand.
- Returns:
New distribution instance with batch dimensions expanded to batch_size.
- has_rsample = True
- icdf(value)[source]
Returns the inverse cumulative density/mass function evaluated at value.
- Args:
value (Tensor):
- log_prob(value)[source]
Returns the log of the probability density/mass function evaluated at value.
- Args:
value (Tensor):
- property mean
Returns the mean of the distribution.
- property mode
Returns the mode of the distribution.
- rsample(sample_shape: Size | List[int] | Tuple[int, ...] = ()) Tensor[source]
Generates a sample_shape shaped reparameterized sample or sample_shape shaped batch of reparameterized samples if the distribution parameters are batched.
- support = Real()
- property variance
Returns the variance of the distribution.
- class skwdro.distributions.Chi2(df, validate_args=None)[source]
Bases:
GammaCreates a Chi-squared distribution parameterized by shape parameter
df. This is exactly equivalent toGamma(alpha=0.5*df, beta=0.5)Example:
>>> # xdoctest: +IGNORE_WANT("non-deterministic") >>> m = Chi2(torch.tensor([1.0])) >>> m.sample() # Chi2 distributed with shape df=1 tensor([ 0.1046])
- Args:
df (float or Tensor): shape parameter of the distribution
- arg_constraints = {'df': GreaterThan(lower_bound=0.0)}
- property df
- expand(batch_shape, _instance=None)[source]
Returns a new distribution instance (or populates an existing instance provided by a derived class) with batch dimensions expanded to batch_shape. This method calls
expandon the distribution’s parameters. As such, this does not allocate new memory for the expanded distribution instance. Additionally, this does not repeat any args checking or parameter broadcasting in __init__.py, when an instance is first created.- Args:
batch_shape (torch.Size): the desired expanded size. _instance: new instance provided by subclasses that
need to override .expand.
- Returns:
New distribution instance with batch dimensions expanded to batch_size.
- class skwdro.distributions.ComposeTransform(parts: List[Transform], cache_size=0)[source]
Bases:
TransformComposes multiple transforms in a chain. The transforms being composed are responsible for caching.
- Args:
parts (list of
Transform): A list of transforms to compose. cache_size (int): Size of cache. If zero, no caching is done. If one,the latest single value is cached. Only 0 and 1 are supported.
- property bijective
bool(x) -> bool
Returns True when the argument x is true, False otherwise. The builtins True and False are the only two instances of the class bool. The class bool is a subclass of the class int, and cannot be subclassed.
- property codomain
- property domain
- forward_shape(shape)[source]
Infers the shape of the forward computation, given the input shape. Defaults to preserving shape.
- inverse_shape(shape)[source]
Infers the shapes of the inverse computation, given the output shape. Defaults to preserving shape.
- log_abs_det_jacobian(x, y)[source]
Computes the log det jacobian log |dy/dx| given input and output.
- property sign
Returns the sign of the determinant of the Jacobian, if applicable. In general this only makes sense for bijective transforms.
- class skwdro.distributions.ContinuousBernoulli(probs=None, logits=None, lims=(0.499, 0.501), validate_args=None)[source]
Bases:
ExponentialFamilyCreates a continuous Bernoulli distribution parameterized by
probsorlogits(but not both).The distribution is supported in [0, 1] and parameterized by ‘probs’ (in (0,1)) or ‘logits’ (real-valued). Note that, unlike the Bernoulli, ‘probs’ does not correspond to a probability and ‘logits’ does not correspond to log-odds, but the same names are used due to the similarity with the Bernoulli. See [1] for more details.
Example:
>>> # xdoctest: +IGNORE_WANT("non-deterministic") >>> m = ContinuousBernoulli(torch.tensor([0.3])) >>> m.sample() tensor([ 0.2538])
- Args:
probs (Number, Tensor): (0,1) valued parameters logits (Number, Tensor): real valued parameters whose sigmoid matches ‘probs’
[1] The continuous Bernoulli: fixing a pervasive error in variational autoencoders, Loaiza-Ganem G and Cunningham JP, NeurIPS 2019. https://arxiv.org/abs/1907.06845
- arg_constraints = {'logits': Real(), 'probs': Interval(lower_bound=0.0, upper_bound=1.0)}
- cdf(value)[source]
Returns the cumulative density/mass function evaluated at value.
- Args:
value (Tensor):
- expand(batch_shape, _instance=None)[source]
Returns a new distribution instance (or populates an existing instance provided by a derived class) with batch dimensions expanded to batch_shape. This method calls
expandon the distribution’s parameters. As such, this does not allocate new memory for the expanded distribution instance. Additionally, this does not repeat any args checking or parameter broadcasting in __init__.py, when an instance is first created.- Args:
batch_shape (torch.Size): the desired expanded size. _instance: new instance provided by subclasses that
need to override .expand.
- Returns:
New distribution instance with batch dimensions expanded to batch_size.
- has_rsample = True
- icdf(value)[source]
Returns the inverse cumulative density/mass function evaluated at value.
- Args:
value (Tensor):
- log_prob(value)[source]
Returns the log of the probability density/mass function evaluated at value.
- Args:
value (Tensor):
- property logits
- property mean
Returns the mean of the distribution.
- property param_shape
- property probs
- rsample(sample_shape: Size | List[int] | Tuple[int, ...] = ()) Tensor[source]
Generates a sample_shape shaped reparameterized sample or sample_shape shaped batch of reparameterized samples if the distribution parameters are batched.
- sample(sample_shape=())[source]
Generates a sample_shape shaped sample or sample_shape shaped batch of samples if the distribution parameters are batched.
- property stddev
Returns the standard deviation of the distribution.
- support = Interval(lower_bound=0.0, upper_bound=1.0)
- property variance
Returns the variance of the distribution.
- class skwdro.distributions.CorrCholeskyTransform(cache_size=0)[source]
Bases:
TransformTransforms an uncontrained real vector
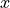 with length
with length 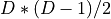 into the
Cholesky factor of a D-dimension correlation matrix. This Cholesky factor is a lower
triangular matrix with positive diagonals and unit Euclidean norm for each row.
The transform is processed as follows:
into the
Cholesky factor of a D-dimension correlation matrix. This Cholesky factor is a lower
triangular matrix with positive diagonals and unit Euclidean norm for each row.
The transform is processed as follows:First we convert x into a lower triangular matrix in row order.
For each row
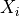 of the lower triangular part, we apply a signed version of
class
of the lower triangular part, we apply a signed version of
class StickBreakingTransformto transform into a
unit Euclidean length vector using the following steps:
- Scales into the interval 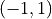 domain:
domain: 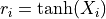 .
- Transforms into an unsigned domain:
.
- Transforms into an unsigned domain: 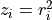 .
- Applies
.
- Applies 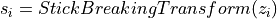 .
- Transforms back into signed domain:
.
- Transforms back into signed domain: 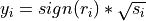 .
.
- bijective = True
- codomain: Constraint = CorrCholesky()
- domain: Constraint = IndependentConstraint(Real(), 1)
- forward_shape(shape)[source]
Infers the shape of the forward computation, given the input shape. Defaults to preserving shape.
- class skwdro.distributions.CumulativeDistributionTransform(distribution, cache_size=0)[source]
Bases:
TransformTransform via the cumulative distribution function of a probability distribution.
- Args:
- distribution (Distribution): Distribution whose cumulative distribution function to use for
the transformation.
Example:
# Construct a Gaussian copula from a multivariate normal. base_dist = MultivariateNormal( loc=torch.zeros(2), scale_tril=LKJCholesky(2).sample(), ) transform = CumulativeDistributionTransform(Normal(0, 1)) copula = TransformedDistribution(base_dist, [transform])
- bijective = True
- codomain: Constraint = Interval(lower_bound=0.0, upper_bound=1.0)
- property domain
- log_abs_det_jacobian(x, y)[source]
Computes the log det jacobian log |dy/dx| given input and output.
- sign = 1
- class skwdro.distributions.Dirac(loc: Tensor, n_batch_dims: int = 0, validate_args: bool | None = None)[source]
Bases:
ExponentialFamily- property arg_constraints: Dict[str, Constraint]
Returns a dictionary from argument names to
Constraintobjects that should be satisfied by each argument of this distribution. Args that are not tensors need not appear in this dict.
- entropy() Tensor[source]
Method to compute the entropy using Bregman divergence of the log normalizer.
- enumerate_support(expand: bool = True) Tensor[source]
Returns tensor containing all values supported by a discrete distribution. The result will enumerate over dimension 0, so the shape of the result will be (cardinality,) + batch_shape + event_shape (where event_shape = () for univariate distributions).
Note that this enumerates over all batched tensors in lock-step [[0, 0], [1, 1], …]. With expand=False, enumeration happens along dim 0, but with the remaining batch dimensions being singleton dimensions, [[0], [1], ...
To iterate over the full Cartesian product use itertools.product(m.enumerate_support()).
- Args:
- expand (bool): whether to expand the support over the
batch dims to match the distribution’s batch_shape.
- Returns:
Tensor iterating over dimension 0.
- expand(batch_shape: Size | List[int] | Tuple[int, ...], _instance=None)[source]
Returns a new distribution instance (or populates an existing instance provided by a derived class) with batch dimensions expanded to batch_shape. This method calls
expandon the distribution’s parameters. As such, this does not allocate new memory for the expanded distribution instance. Additionally, this does not repeat any args checking or parameter broadcasting in __init__.py, when an instance is first created.- Args:
batch_shape (torch.Size): the desired expanded size. _instance: new instance provided by subclasses that
need to override .expand.
- Returns:
New distribution instance with batch dimensions expanded to batch_size.
- has_rsample = True
- loc: Tensor
- log_prob(value: Tensor) Tensor[source]
Returns the log of the probability density/mass function evaluated at value.
- Args:
value (Tensor):
- property mean: Tensor
Returns the mean of the distribution.
- property mode: Tensor
Returns the mode of the distribution.
- perplexity() Tensor[source]
Returns perplexity of distribution, batched over batch_shape.
- Returns:
Tensor of shape batch_shape.
- rsample(sample_shape: Size | List[int] | Tuple[int, ...] = ()) Tensor[source]
Generates a sample_shape shaped reparameterized sample or sample_shape shaped batch of reparameterized samples if the distribution parameters are batched.
- property support: Constraint | None
Returns a
Constraintobject representing this distribution’s support.
- property variance: Tensor
Returns the variance of the distribution.
- class skwdro.distributions.Dirichlet(concentration, validate_args=None)[source]
Bases:
ExponentialFamilyCreates a Dirichlet distribution parameterized by concentration
concentration.Example:
>>> # xdoctest: +IGNORE_WANT("non-deterministic") >>> m = Dirichlet(torch.tensor([0.5, 0.5])) >>> m.sample() # Dirichlet distributed with concentration [0.5, 0.5] tensor([ 0.1046, 0.8954])
- Args:
- concentration (Tensor): concentration parameter of the distribution
(often referred to as alpha)
- arg_constraints = {'concentration': IndependentConstraint(GreaterThan(lower_bound=0.0), 1)}
- expand(batch_shape, _instance=None)[source]
Returns a new distribution instance (or populates an existing instance provided by a derived class) with batch dimensions expanded to batch_shape. This method calls
expandon the distribution’s parameters. As such, this does not allocate new memory for the expanded distribution instance. Additionally, this does not repeat any args checking or parameter broadcasting in __init__.py, when an instance is first created.- Args:
batch_shape (torch.Size): the desired expanded size. _instance: new instance provided by subclasses that
need to override .expand.
- Returns:
New distribution instance with batch dimensions expanded to batch_size.
- has_rsample = True
- log_prob(value)[source]
Returns the log of the probability density/mass function evaluated at value.
- Args:
value (Tensor):
- property mean
Returns the mean of the distribution.
- property mode
Returns the mode of the distribution.
- rsample(sample_shape: Size | List[int] | Tuple[int, ...] = ()) Tensor[source]
Generates a sample_shape shaped reparameterized sample or sample_shape shaped batch of reparameterized samples if the distribution parameters are batched.
- support = Simplex()
- property variance
Returns the variance of the distribution.
- class skwdro.distributions.Distribution(batch_shape: Size = (), event_shape: Size = (), validate_args: bool | None = None)[source]
Bases:
objectDistribution is the abstract base class for probability distributions.
- property arg_constraints: Dict[str, Constraint]
Returns a dictionary from argument names to
Constraintobjects that should be satisfied by each argument of this distribution. Args that are not tensors need not appear in this dict.
- property batch_shape: Size
Returns the shape over which parameters are batched.
- cdf(value: Tensor) Tensor[source]
Returns the cumulative density/mass function evaluated at value.
- Args:
value (Tensor):
- entropy() Tensor[source]
Returns entropy of distribution, batched over batch_shape.
- Returns:
Tensor of shape batch_shape.
- enumerate_support(expand: bool = True) Tensor[source]
Returns tensor containing all values supported by a discrete distribution. The result will enumerate over dimension 0, so the shape of the result will be (cardinality,) + batch_shape + event_shape (where event_shape = () for univariate distributions).
Note that this enumerates over all batched tensors in lock-step [[0, 0], [1, 1], …]. With expand=False, enumeration happens along dim 0, but with the remaining batch dimensions being singleton dimensions, [[0], [1], ...
To iterate over the full Cartesian product use itertools.product(m.enumerate_support()).
- Args:
- expand (bool): whether to expand the support over the
batch dims to match the distribution’s batch_shape.
- Returns:
Tensor iterating over dimension 0.
- property event_shape: Size
Returns the shape of a single sample (without batching).
- expand(batch_shape: Size | List[int] | Tuple[int, ...], _instance=None)[source]
Returns a new distribution instance (or populates an existing instance provided by a derived class) with batch dimensions expanded to batch_shape. This method calls
expandon the distribution’s parameters. As such, this does not allocate new memory for the expanded distribution instance. Additionally, this does not repeat any args checking or parameter broadcasting in __init__.py, when an instance is first created.- Args:
batch_shape (torch.Size): the desired expanded size. _instance: new instance provided by subclasses that
need to override .expand.
- Returns:
New distribution instance with batch dimensions expanded to batch_size.
- has_enumerate_support = False
- has_rsample = False
- icdf(value: Tensor) Tensor[source]
Returns the inverse cumulative density/mass function evaluated at value.
- Args:
value (Tensor):
- log_prob(value: Tensor) Tensor[source]
Returns the log of the probability density/mass function evaluated at value.
- Args:
value (Tensor):
- property mean: Tensor
Returns the mean of the distribution.
- property mode: Tensor
Returns the mode of the distribution.
- perplexity() Tensor[source]
Returns perplexity of distribution, batched over batch_shape.
- Returns:
Tensor of shape batch_shape.
- rsample(sample_shape: Size | List[int] | Tuple[int, ...] = ()) Tensor[source]
Generates a sample_shape shaped reparameterized sample or sample_shape shaped batch of reparameterized samples if the distribution parameters are batched.
- sample(sample_shape: Size | List[int] | Tuple[int, ...] = ()) Tensor[source]
Generates a sample_shape shaped sample or sample_shape shaped batch of samples if the distribution parameters are batched.
- sample_n(n: int) Tensor[source]
Generates n samples or n batches of samples if the distribution parameters are batched.
- static set_default_validate_args(value: bool) None[source]
Sets whether validation is enabled or disabled.
The default behavior mimics Python’s
assertstatement: validation is on by default, but is disabled if Python is run in optimized mode (viapython -O). Validation may be expensive, so you may want to disable it once a model is working.- Args:
value (bool): Whether to enable validation.
- property stddev: Tensor
Returns the standard deviation of the distribution.
- property variance: Tensor
Returns the variance of the distribution.
- class skwdro.distributions.ExpTransform(cache_size=0)[source]
Bases:
TransformTransform via the mapping
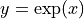 .
.- bijective = True
- codomain: Constraint = GreaterThan(lower_bound=0.0)
- domain: Constraint = Real()
- log_abs_det_jacobian(x, y)[source]
Computes the log det jacobian log |dy/dx| given input and output.
- sign = 1
- class skwdro.distributions.Exponential(rate, validate_args=None)[source]
Bases:
ExponentialFamilyCreates a Exponential distribution parameterized by
rate.Example:
>>> # xdoctest: +IGNORE_WANT("non-deterministic") >>> m = Exponential(torch.tensor([1.0])) >>> m.sample() # Exponential distributed with rate=1 tensor([ 0.1046])
- Args:
rate (float or Tensor): rate = 1 / scale of the distribution
- arg_constraints = {'rate': GreaterThan(lower_bound=0.0)}
- cdf(value)[source]
Returns the cumulative density/mass function evaluated at value.
- Args:
value (Tensor):
- expand(batch_shape, _instance=None)[source]
Returns a new distribution instance (or populates an existing instance provided by a derived class) with batch dimensions expanded to batch_shape. This method calls
expandon the distribution’s parameters. As such, this does not allocate new memory for the expanded distribution instance. Additionally, this does not repeat any args checking or parameter broadcasting in __init__.py, when an instance is first created.- Args:
batch_shape (torch.Size): the desired expanded size. _instance: new instance provided by subclasses that
need to override .expand.
- Returns:
New distribution instance with batch dimensions expanded to batch_size.
- has_rsample = True
- icdf(value)[source]
Returns the inverse cumulative density/mass function evaluated at value.
- Args:
value (Tensor):
- log_prob(value)[source]
Returns the log of the probability density/mass function evaluated at value.
- Args:
value (Tensor):
- property mean
Returns the mean of the distribution.
- property mode
Returns the mode of the distribution.
- rsample(sample_shape: Size | List[int] | Tuple[int, ...] = ()) Tensor[source]
Generates a sample_shape shaped reparameterized sample or sample_shape shaped batch of reparameterized samples if the distribution parameters are batched.
- property stddev
Returns the standard deviation of the distribution.
- support = GreaterThanEq(lower_bound=0.0)
- property variance
Returns the variance of the distribution.
- class skwdro.distributions.ExponentialFamily(batch_shape: Size = (), event_shape: Size = (), validate_args: bool | None = None)[source]
Bases:
DistributionExponentialFamily is the abstract base class for probability distributions belonging to an exponential family, whose probability mass/density function has the form is defined below
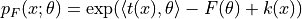
where
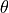 denotes the natural parameters,
denotes the natural parameters, 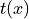 denotes the sufficient statistic,
denotes the sufficient statistic,
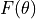 is the log normalizer function for a given family and
is the log normalizer function for a given family and 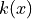 is the carrier
measure.
is the carrier
measure.- Note:
This class is an intermediary between the Distribution class and distributions which belong to an exponential family mainly to check the correctness of the .entropy() and analytic KL divergence methods. We use this class to compute the entropy and KL divergence using the AD framework and Bregman divergences (courtesy of: Frank Nielsen and Richard Nock, Entropies and Cross-entropies of Exponential Families).
- class skwdro.distributions.FisherSnedecor(df1, df2, validate_args=None)[source]
Bases:
DistributionCreates a Fisher-Snedecor distribution parameterized by
df1anddf2.Example:
>>> # xdoctest: +IGNORE_WANT("non-deterministic") >>> m = FisherSnedecor(torch.tensor([1.0]), torch.tensor([2.0])) >>> m.sample() # Fisher-Snedecor-distributed with df1=1 and df2=2 tensor([ 0.2453])
- Args:
df1 (float or Tensor): degrees of freedom parameter 1 df2 (float or Tensor): degrees of freedom parameter 2
- arg_constraints = {'df1': GreaterThan(lower_bound=0.0), 'df2': GreaterThan(lower_bound=0.0)}
- expand(batch_shape, _instance=None)[source]
Returns a new distribution instance (or populates an existing instance provided by a derived class) with batch dimensions expanded to batch_shape. This method calls
expandon the distribution’s parameters. As such, this does not allocate new memory for the expanded distribution instance. Additionally, this does not repeat any args checking or parameter broadcasting in __init__.py, when an instance is first created.- Args:
batch_shape (torch.Size): the desired expanded size. _instance: new instance provided by subclasses that
need to override .expand.
- Returns:
New distribution instance with batch dimensions expanded to batch_size.
- has_rsample = True
- log_prob(value)[source]
Returns the log of the probability density/mass function evaluated at value.
- Args:
value (Tensor):
- property mean
Returns the mean of the distribution.
- property mode
Returns the mode of the distribution.
- rsample(sample_shape: Size | List[int] | Tuple[int, ...] = ()) Tensor[source]
Generates a sample_shape shaped reparameterized sample or sample_shape shaped batch of reparameterized samples if the distribution parameters are batched.
- support = GreaterThan(lower_bound=0.0)
- property variance
Returns the variance of the distribution.
- class skwdro.distributions.Gamma(concentration, rate, validate_args=None)[source]
Bases:
ExponentialFamilyCreates a Gamma distribution parameterized by shape
concentrationandrate.Example:
>>> # xdoctest: +IGNORE_WANT("non-deterministic") >>> m = Gamma(torch.tensor([1.0]), torch.tensor([1.0])) >>> m.sample() # Gamma distributed with concentration=1 and rate=1 tensor([ 0.1046])
- Args:
- concentration (float or Tensor): shape parameter of the distribution
(often referred to as alpha)
- rate (float or Tensor): rate = 1 / scale of the distribution
(often referred to as beta)
- arg_constraints = {'concentration': GreaterThan(lower_bound=0.0), 'rate': GreaterThan(lower_bound=0.0)}
- cdf(value)[source]
Returns the cumulative density/mass function evaluated at value.
- Args:
value (Tensor):
- expand(batch_shape, _instance=None)[source]
Returns a new distribution instance (or populates an existing instance provided by a derived class) with batch dimensions expanded to batch_shape. This method calls
expandon the distribution’s parameters. As such, this does not allocate new memory for the expanded distribution instance. Additionally, this does not repeat any args checking or parameter broadcasting in __init__.py, when an instance is first created.- Args:
batch_shape (torch.Size): the desired expanded size. _instance: new instance provided by subclasses that
need to override .expand.
- Returns:
New distribution instance with batch dimensions expanded to batch_size.
- has_rsample = True
- log_prob(value)[source]
Returns the log of the probability density/mass function evaluated at value.
- Args:
value (Tensor):
- property mean
Returns the mean of the distribution.
- property mode
Returns the mode of the distribution.
- rsample(sample_shape: Size | List[int] | Tuple[int, ...] = ()) Tensor[source]
Generates a sample_shape shaped reparameterized sample or sample_shape shaped batch of reparameterized samples if the distribution parameters are batched.
- support = GreaterThanEq(lower_bound=0.0)
- property variance
Returns the variance of the distribution.
- class skwdro.distributions.Geometric(probs=None, logits=None, validate_args=None)[source]
Bases:
DistributionCreates a Geometric distribution parameterized by
probs, whereprobsis the probability of success of Bernoulli trials.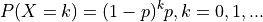
Note
torch.distributions.geometric.Geometric()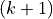 -th trial is the first success
hence draws samples in
-th trial is the first success
hence draws samples in 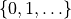 , whereas
, whereas
torch.Tensor.geometric_()k-th trial is the first success hence draws samples in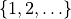 .
.Example:
>>> # xdoctest: +IGNORE_WANT("non-deterministic") >>> m = Geometric(torch.tensor([0.3])) >>> m.sample() # underlying Bernoulli has 30% chance 1; 70% chance 0 tensor([ 2.])
- Args:
probs (Number, Tensor): the probability of sampling 1. Must be in range (0, 1] logits (Number, Tensor): the log-odds of sampling 1.
- arg_constraints = {'logits': Real(), 'probs': Interval(lower_bound=0.0, upper_bound=1.0)}
- entropy()[source]
Returns entropy of distribution, batched over batch_shape.
- Returns:
Tensor of shape batch_shape.
- expand(batch_shape, _instance=None)[source]
Returns a new distribution instance (or populates an existing instance provided by a derived class) with batch dimensions expanded to batch_shape. This method calls
expandon the distribution’s parameters. As such, this does not allocate new memory for the expanded distribution instance. Additionally, this does not repeat any args checking or parameter broadcasting in __init__.py, when an instance is first created.- Args:
batch_shape (torch.Size): the desired expanded size. _instance: new instance provided by subclasses that
need to override .expand.
- Returns:
New distribution instance with batch dimensions expanded to batch_size.
- log_prob(value)[source]
Returns the log of the probability density/mass function evaluated at value.
- Args:
value (Tensor):
- property logits
- property mean
Returns the mean of the distribution.
- property mode
Returns the mode of the distribution.
- property probs
- sample(sample_shape=())[source]
Generates a sample_shape shaped sample or sample_shape shaped batch of samples if the distribution parameters are batched.
- support = IntegerGreaterThan(lower_bound=0)
- property variance
Returns the variance of the distribution.
- class skwdro.distributions.Gumbel(loc, scale, validate_args=None)[source]
Bases:
TransformedDistributionSamples from a Gumbel Distribution.
Examples:
>>> # xdoctest: +IGNORE_WANT("non-deterministic") >>> m = Gumbel(torch.tensor([1.0]), torch.tensor([2.0])) >>> m.sample() # sample from Gumbel distribution with loc=1, scale=2 tensor([ 1.0124])
- Args:
loc (float or Tensor): Location parameter of the distribution scale (float or Tensor): Scale parameter of the distribution
- arg_constraints: Dict[str, constraints.Constraint] = {'loc': Real(), 'scale': GreaterThan(lower_bound=0.0)}
- entropy()[source]
Returns entropy of distribution, batched over batch_shape.
- Returns:
Tensor of shape batch_shape.
- expand(batch_shape, _instance=None)[source]
Returns a new distribution instance (or populates an existing instance provided by a derived class) with batch dimensions expanded to batch_shape. This method calls
expandon the distribution’s parameters. As such, this does not allocate new memory for the expanded distribution instance. Additionally, this does not repeat any args checking or parameter broadcasting in __init__.py, when an instance is first created.- Args:
batch_shape (torch.Size): the desired expanded size. _instance: new instance provided by subclasses that
need to override .expand.
- Returns:
New distribution instance with batch dimensions expanded to batch_size.
- log_prob(value)[source]
Scores the sample by inverting the transform(s) and computing the score using the score of the base distribution and the log abs det jacobian.
- property mean
Returns the mean of the distribution.
- property mode
Returns the mode of the distribution.
- property stddev
Returns the standard deviation of the distribution.
- support = Real()
- property variance
Returns the variance of the distribution.
- class skwdro.distributions.HalfCauchy(scale, validate_args=None)[source]
Bases:
TransformedDistributionCreates a half-Cauchy distribution parameterized by scale where:
X ~ Cauchy(0, scale) Y = |X| ~ HalfCauchy(scale)
Example:
>>> # xdoctest: +IGNORE_WANT("non-deterministic") >>> m = HalfCauchy(torch.tensor([1.0])) >>> m.sample() # half-cauchy distributed with scale=1 tensor([ 2.3214])
- Args:
scale (float or Tensor): scale of the full Cauchy distribution
- cdf(value)[source]
Computes the cumulative distribution function by inverting the transform(s) and computing the score of the base distribution.
- entropy()[source]
Returns entropy of distribution, batched over batch_shape.
- Returns:
Tensor of shape batch_shape.
- expand(batch_shape, _instance=None)[source]
Returns a new distribution instance (or populates an existing instance provided by a derived class) with batch dimensions expanded to batch_shape. This method calls
expandon the distribution’s parameters. As such, this does not allocate new memory for the expanded distribution instance. Additionally, this does not repeat any args checking or parameter broadcasting in __init__.py, when an instance is first created.- Args:
batch_shape (torch.Size): the desired expanded size. _instance: new instance provided by subclasses that
need to override .expand.
- Returns:
New distribution instance with batch dimensions expanded to batch_size.
- has_rsample = True
- icdf(prob)[source]
Computes the inverse cumulative distribution function using transform(s) and computing the score of the base distribution.
- log_prob(value)[source]
Scores the sample by inverting the transform(s) and computing the score using the score of the base distribution and the log abs det jacobian.
- property mean
Returns the mean of the distribution.
- property mode
Returns the mode of the distribution.
- property scale
- support = GreaterThanEq(lower_bound=0.0)
- property variance
Returns the variance of the distribution.
- class skwdro.distributions.HalfNormal(scale, validate_args=None)[source]
Bases:
TransformedDistributionCreates a half-normal distribution parameterized by scale where:
X ~ Normal(0, scale) Y = |X| ~ HalfNormal(scale)
Example:
>>> # xdoctest: +IGNORE_WANT("non-deterministic") >>> m = HalfNormal(torch.tensor([1.0])) >>> m.sample() # half-normal distributed with scale=1 tensor([ 0.1046])
- Args:
scale (float or Tensor): scale of the full Normal distribution
- cdf(value)[source]
Computes the cumulative distribution function by inverting the transform(s) and computing the score of the base distribution.
- entropy()[source]
Returns entropy of distribution, batched over batch_shape.
- Returns:
Tensor of shape batch_shape.
- expand(batch_shape, _instance=None)[source]
Returns a new distribution instance (or populates an existing instance provided by a derived class) with batch dimensions expanded to batch_shape. This method calls
expandon the distribution’s parameters. As such, this does not allocate new memory for the expanded distribution instance. Additionally, this does not repeat any args checking or parameter broadcasting in __init__.py, when an instance is first created.- Args:
batch_shape (torch.Size): the desired expanded size. _instance: new instance provided by subclasses that
need to override .expand.
- Returns:
New distribution instance with batch dimensions expanded to batch_size.
- has_rsample = True
- icdf(prob)[source]
Computes the inverse cumulative distribution function using transform(s) and computing the score of the base distribution.
- log_prob(value)[source]
Scores the sample by inverting the transform(s) and computing the score using the score of the base distribution and the log abs det jacobian.
- property mean
Returns the mean of the distribution.
- property mode
Returns the mode of the distribution.
- property scale
- support = GreaterThanEq(lower_bound=0.0)
- property variance
Returns the variance of the distribution.
- class skwdro.distributions.Independent(base_distribution, reinterpreted_batch_ndims, validate_args=None)[source]
Bases:
DistributionReinterprets some of the batch dims of a distribution as event dims.
This is mainly useful for changing the shape of the result of
log_prob(). For example to create a diagonal Normal distribution with the same shape as a Multivariate Normal distribution (so they are interchangeable), you can:>>> from torch.distributions.multivariate_normal import MultivariateNormal >>> from torch.distributions.normal import Normal >>> loc = torch.zeros(3) >>> scale = torch.ones(3) >>> mvn = MultivariateNormal(loc, scale_tril=torch.diag(scale)) >>> [mvn.batch_shape, mvn.event_shape] [torch.Size([]), torch.Size([3])] >>> normal = Normal(loc, scale) >>> [normal.batch_shape, normal.event_shape] [torch.Size([3]), torch.Size([])] >>> diagn = Independent(normal, 1) >>> [diagn.batch_shape, diagn.event_shape] [torch.Size([]), torch.Size([3])]
- Args:
- base_distribution (torch.distributions.distribution.Distribution): a
base distribution
- reinterpreted_batch_ndims (int): the number of batch dims to
reinterpret as event dims
- entropy()[source]
Returns entropy of distribution, batched over batch_shape.
- Returns:
Tensor of shape batch_shape.
- enumerate_support(expand=True)[source]
Returns tensor containing all values supported by a discrete distribution. The result will enumerate over dimension 0, so the shape of the result will be (cardinality,) + batch_shape + event_shape (where event_shape = () for univariate distributions).
Note that this enumerates over all batched tensors in lock-step [[0, 0], [1, 1], …]. With expand=False, enumeration happens along dim 0, but with the remaining batch dimensions being singleton dimensions, [[0], [1], ...
To iterate over the full Cartesian product use itertools.product(m.enumerate_support()).
- Args:
- expand (bool): whether to expand the support over the
batch dims to match the distribution’s batch_shape.
- Returns:
Tensor iterating over dimension 0.
- expand(batch_shape, _instance=None)[source]
Returns a new distribution instance (or populates an existing instance provided by a derived class) with batch dimensions expanded to batch_shape. This method calls
expandon the distribution’s parameters. As such, this does not allocate new memory for the expanded distribution instance. Additionally, this does not repeat any args checking or parameter broadcasting in __init__.py, when an instance is first created.- Args:
batch_shape (torch.Size): the desired expanded size. _instance: new instance provided by subclasses that
need to override .expand.
- Returns:
New distribution instance with batch dimensions expanded to batch_size.
- property has_enumerate_support
bool(x) -> bool
Returns True when the argument x is true, False otherwise. The builtins True and False are the only two instances of the class bool. The class bool is a subclass of the class int, and cannot be subclassed.
- property has_rsample
bool(x) -> bool
Returns True when the argument x is true, False otherwise. The builtins True and False are the only two instances of the class bool. The class bool is a subclass of the class int, and cannot be subclassed.
- log_prob(value)[source]
Returns the log of the probability density/mass function evaluated at value.
- Args:
value (Tensor):
- property mean
Returns the mean of the distribution.
- property mode
Returns the mode of the distribution.
- rsample(sample_shape: Size | List[int] | Tuple[int, ...] = ()) Tensor[source]
Generates a sample_shape shaped reparameterized sample or sample_shape shaped batch of reparameterized samples if the distribution parameters are batched.
- sample(sample_shape=())[source]
Generates a sample_shape shaped sample or sample_shape shaped batch of samples if the distribution parameters are batched.
- property support
Returns a
Constraintobject representing this distribution’s support.
- property variance
Returns the variance of the distribution.
- class skwdro.distributions.IndependentTransform(base_transform, reinterpreted_batch_ndims, cache_size=0)[source]
Bases:
TransformWrapper around another transform to treat
reinterpreted_batch_ndims-many extra of the right most dimensions as dependent. This has no effect on the forward or backward transforms, but does sum outreinterpreted_batch_ndims-many of the rightmost dimensions inlog_abs_det_jacobian().- Args:
base_transform (
Transform): A base transform. reinterpreted_batch_ndims (int): The number of extra rightmostdimensions to treat as dependent.
- property bijective
bool(x) -> bool
Returns True when the argument x is true, False otherwise. The builtins True and False are the only two instances of the class bool. The class bool is a subclass of the class int, and cannot be subclassed.
- property codomain
- property domain
- forward_shape(shape)[source]
Infers the shape of the forward computation, given the input shape. Defaults to preserving shape.
- inverse_shape(shape)[source]
Infers the shapes of the inverse computation, given the output shape. Defaults to preserving shape.
- log_abs_det_jacobian(x, y)[source]
Computes the log det jacobian log |dy/dx| given input and output.
- property sign
Returns the sign of the determinant of the Jacobian, if applicable. In general this only makes sense for bijective transforms.
- class skwdro.distributions.InverseGamma(concentration, rate, validate_args=None)[source]
Bases:
TransformedDistributionCreates an inverse gamma distribution parameterized by
concentrationandratewhere:X ~ Gamma(concentration, rate) Y = 1 / X ~ InverseGamma(concentration, rate)
Example:
>>> # xdoctest: +IGNORE_WANT("non-deterinistic") >>> m = InverseGamma(torch.tensor([2.0]), torch.tensor([3.0])) >>> m.sample() tensor([ 1.2953])
- Args:
- concentration (float or Tensor): shape parameter of the distribution
(often referred to as alpha)
- rate (float or Tensor): rate = 1 / scale of the distribution
(often referred to as beta)
- arg_constraints: Dict[str, constraints.Constraint] = {'concentration': GreaterThan(lower_bound=0.0), 'rate': GreaterThan(lower_bound=0.0)}
- property concentration
- entropy()[source]
Returns entropy of distribution, batched over batch_shape.
- Returns:
Tensor of shape batch_shape.
- expand(batch_shape, _instance=None)[source]
Returns a new distribution instance (or populates an existing instance provided by a derived class) with batch dimensions expanded to batch_shape. This method calls
expandon the distribution’s parameters. As such, this does not allocate new memory for the expanded distribution instance. Additionally, this does not repeat any args checking or parameter broadcasting in __init__.py, when an instance is first created.- Args:
batch_shape (torch.Size): the desired expanded size. _instance: new instance provided by subclasses that
need to override .expand.
- Returns:
New distribution instance with batch dimensions expanded to batch_size.
- has_rsample = True
- property mean
Returns the mean of the distribution.
- property mode
Returns the mode of the distribution.
- property rate
- support = GreaterThan(lower_bound=0.0)
- property variance
Returns the variance of the distribution.
- class skwdro.distributions.Kumaraswamy(concentration1, concentration0, validate_args=None)[source]
Bases:
TransformedDistributionSamples from a Kumaraswamy distribution.
Example:
>>> # xdoctest: +IGNORE_WANT("non-deterministic") >>> m = Kumaraswamy(torch.tensor([1.0]), torch.tensor([1.0])) >>> m.sample() # sample from a Kumaraswamy distribution with concentration alpha=1 and beta=1 tensor([ 0.1729])
- Args:
- concentration1 (float or Tensor): 1st concentration parameter of the distribution
(often referred to as alpha)
- concentration0 (float or Tensor): 2nd concentration parameter of the distribution
(often referred to as beta)
- arg_constraints: Dict[str, constraints.Constraint] = {'concentration0': GreaterThan(lower_bound=0.0), 'concentration1': GreaterThan(lower_bound=0.0)}
- entropy()[source]
Returns entropy of distribution, batched over batch_shape.
- Returns:
Tensor of shape batch_shape.
- expand(batch_shape, _instance=None)[source]
Returns a new distribution instance (or populates an existing instance provided by a derived class) with batch dimensions expanded to batch_shape. This method calls
expandon the distribution’s parameters. As such, this does not allocate new memory for the expanded distribution instance. Additionally, this does not repeat any args checking or parameter broadcasting in __init__.py, when an instance is first created.- Args:
batch_shape (torch.Size): the desired expanded size. _instance: new instance provided by subclasses that
need to override .expand.
- Returns:
New distribution instance with batch dimensions expanded to batch_size.
- has_rsample = True
- property mean
Returns the mean of the distribution.
- property mode
Returns the mode of the distribution.
- support = Interval(lower_bound=0.0, upper_bound=1.0)
- property variance
Returns the variance of the distribution.
- class skwdro.distributions.LKJCholesky(dim, concentration=1.0, validate_args=None)[source]
Bases:
DistributionLKJ distribution for lower Cholesky factor of correlation matrices. The distribution is controlled by
concentrationparameter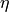 to make the probability of the correlation matrix
to make the probability of the correlation matrix 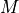 generated from
a Cholesky factor proportional to
generated from
a Cholesky factor proportional to 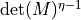 . Because of that,
when
. Because of that,
when concentration == 1, we have a uniform distribution over Cholesky factors of correlation matrices:L ~ LKJCholesky(dim, concentration) X = L @ L' ~ LKJCorr(dim, concentration)
Note that this distribution samples the Cholesky factor of correlation matrices and not the correlation matrices themselves and thereby differs slightly from the derivations in [1] for the LKJCorr distribution. For sampling, this uses the Onion method from [1] Section 3.
Example:
>>> # xdoctest: +IGNORE_WANT("non-deterministic") >>> l = LKJCholesky(3, 0.5) >>> l.sample() # l @ l.T is a sample of a correlation 3x3 matrix tensor([[ 1.0000, 0.0000, 0.0000], [ 0.3516, 0.9361, 0.0000], [-0.1899, 0.4748, 0.8593]])
- Args:
dimension (dim): dimension of the matrices concentration (float or Tensor): concentration/shape parameter of the
distribution (often referred to as eta)
References
[1] Generating random correlation matrices based on vines and extended onion method (2009), Daniel Lewandowski, Dorota Kurowicka, Harry Joe. Journal of Multivariate Analysis. 100. 10.1016/j.jmva.2009.04.008
- arg_constraints = {'concentration': GreaterThan(lower_bound=0.0)}
- expand(batch_shape, _instance=None)[source]
Returns a new distribution instance (or populates an existing instance provided by a derived class) with batch dimensions expanded to batch_shape. This method calls
expandon the distribution’s parameters. As such, this does not allocate new memory for the expanded distribution instance. Additionally, this does not repeat any args checking or parameter broadcasting in __init__.py, when an instance is first created.- Args:
batch_shape (torch.Size): the desired expanded size. _instance: new instance provided by subclasses that
need to override .expand.
- Returns:
New distribution instance with batch dimensions expanded to batch_size.
- log_prob(value)[source]
Returns the log of the probability density/mass function evaluated at value.
- Args:
value (Tensor):
- sample(sample_shape=())[source]
Generates a sample_shape shaped sample or sample_shape shaped batch of samples if the distribution parameters are batched.
- support = CorrCholesky()
- class skwdro.distributions.Laplace(loc, scale, validate_args=None)[source]
Bases:
DistributionCreates a Laplace distribution parameterized by
locandscale.Example:
>>> # xdoctest: +IGNORE_WANT("non-deterministic") >>> m = Laplace(torch.tensor([0.0]), torch.tensor([1.0])) >>> m.sample() # Laplace distributed with loc=0, scale=1 tensor([ 0.1046])
- Args:
loc (float or Tensor): mean of the distribution scale (float or Tensor): scale of the distribution
- arg_constraints = {'loc': Real(), 'scale': GreaterThan(lower_bound=0.0)}
- cdf(value)[source]
Returns the cumulative density/mass function evaluated at value.
- Args:
value (Tensor):
- entropy()[source]
Returns entropy of distribution, batched over batch_shape.
- Returns:
Tensor of shape batch_shape.
- expand(batch_shape, _instance=None)[source]
Returns a new distribution instance (or populates an existing instance provided by a derived class) with batch dimensions expanded to batch_shape. This method calls
expandon the distribution’s parameters. As such, this does not allocate new memory for the expanded distribution instance. Additionally, this does not repeat any args checking or parameter broadcasting in __init__.py, when an instance is first created.- Args:
batch_shape (torch.Size): the desired expanded size. _instance: new instance provided by subclasses that
need to override .expand.
- Returns:
New distribution instance with batch dimensions expanded to batch_size.
- has_rsample = True
- icdf(value)[source]
Returns the inverse cumulative density/mass function evaluated at value.
- Args:
value (Tensor):
- log_prob(value)[source]
Returns the log of the probability density/mass function evaluated at value.
- Args:
value (Tensor):
- property mean
Returns the mean of the distribution.
- property mode
Returns the mode of the distribution.
- rsample(sample_shape: Size | List[int] | Tuple[int, ...] = ()) Tensor[source]
Generates a sample_shape shaped reparameterized sample or sample_shape shaped batch of reparameterized samples if the distribution parameters are batched.
- property stddev
Returns the standard deviation of the distribution.
- support = Real()
- property variance
Returns the variance of the distribution.
- class skwdro.distributions.LogNormal(loc, scale, validate_args=None)[source]
Bases:
TransformedDistributionCreates a log-normal distribution parameterized by
locandscalewhere:X ~ Normal(loc, scale) Y = exp(X) ~ LogNormal(loc, scale)
Example:
>>> # xdoctest: +IGNORE_WANT("non-deterministic") >>> m = LogNormal(torch.tensor([0.0]), torch.tensor([1.0])) >>> m.sample() # log-normal distributed with mean=0 and stddev=1 tensor([ 0.1046])
- Args:
loc (float or Tensor): mean of log of distribution scale (float or Tensor): standard deviation of log of the distribution
- arg_constraints: Dict[str, constraints.Constraint] = {'loc': Real(), 'scale': GreaterThan(lower_bound=0.0)}
- entropy()[source]
Returns entropy of distribution, batched over batch_shape.
- Returns:
Tensor of shape batch_shape.
- expand(batch_shape, _instance=None)[source]
Returns a new distribution instance (or populates an existing instance provided by a derived class) with batch dimensions expanded to batch_shape. This method calls
expandon the distribution’s parameters. As such, this does not allocate new memory for the expanded distribution instance. Additionally, this does not repeat any args checking or parameter broadcasting in __init__.py, when an instance is first created.- Args:
batch_shape (torch.Size): the desired expanded size. _instance: new instance provided by subclasses that
need to override .expand.
- Returns:
New distribution instance with batch dimensions expanded to batch_size.
- has_rsample = True
- property loc
- property mean
Returns the mean of the distribution.
- property mode
Returns the mode of the distribution.
- property scale
- support = GreaterThan(lower_bound=0.0)
- property variance
Returns the variance of the distribution.
- class skwdro.distributions.LogisticNormal(loc, scale, validate_args=None)[source]
Bases:
TransformedDistributionCreates a logistic-normal distribution parameterized by
locandscalethat define the base Normal distribution transformed with the StickBreakingTransform such that:X ~ LogisticNormal(loc, scale) Y = log(X / (1 - X.cumsum(-1)))[..., :-1] ~ Normal(loc, scale)
- Args:
loc (float or Tensor): mean of the base distribution scale (float or Tensor): standard deviation of the base distribution
Example:
>>> # logistic-normal distributed with mean=(0, 0, 0) and stddev=(1, 1, 1) >>> # of the base Normal distribution >>> # xdoctest: +IGNORE_WANT("non-deterministic") >>> m = LogisticNormal(torch.tensor([0.0] * 3), torch.tensor([1.0] * 3)) >>> m.sample() tensor([ 0.7653, 0.0341, 0.0579, 0.1427])
- arg_constraints: Dict[str, constraints.Constraint] = {'loc': Real(), 'scale': GreaterThan(lower_bound=0.0)}
- expand(batch_shape, _instance=None)[source]
Returns a new distribution instance (or populates an existing instance provided by a derived class) with batch dimensions expanded to batch_shape. This method calls
expandon the distribution’s parameters. As such, this does not allocate new memory for the expanded distribution instance. Additionally, this does not repeat any args checking or parameter broadcasting in __init__.py, when an instance is first created.- Args:
batch_shape (torch.Size): the desired expanded size. _instance: new instance provided by subclasses that
need to override .expand.
- Returns:
New distribution instance with batch dimensions expanded to batch_size.
- has_rsample = True
- property loc
- property scale
- support = Simplex()
- class skwdro.distributions.LowRankMultivariateNormal(loc, cov_factor, cov_diag, validate_args=None)[source]
Bases:
DistributionCreates a multivariate normal distribution with covariance matrix having a low-rank form parameterized by
cov_factorandcov_diag:covariance_matrix = cov_factor @ cov_factor.T + cov_diag
- Example:
>>> # xdoctest: +REQUIRES(env:TORCH_DOCTEST_LAPACK) >>> # xdoctest: +IGNORE_WANT("non-deterministic") >>> m = LowRankMultivariateNormal(torch.zeros(2), torch.tensor([[1.], [0.]]), torch.ones(2)) >>> m.sample() # normally distributed with mean=`[0,0]`, cov_factor=`[[1],[0]]`, cov_diag=`[1,1]` tensor([-0.2102, -0.5429])
- Args:
loc (Tensor): mean of the distribution with shape batch_shape + event_shape cov_factor (Tensor): factor part of low-rank form of covariance matrix with shape
batch_shape + event_shape + (rank,)
- cov_diag (Tensor): diagonal part of low-rank form of covariance matrix with shape
batch_shape + event_shape
- Note:
The computation for determinant and inverse of covariance matrix is avoided when cov_factor.shape[1] << cov_factor.shape[0] thanks to Woodbury matrix identity and matrix determinant lemma. Thanks to these formulas, we just need to compute the determinant and inverse of the small size “capacitance” matrix:
capacitance = I + cov_factor.T @ inv(cov_diag) @ cov_factor
- arg_constraints = {'cov_diag': IndependentConstraint(GreaterThan(lower_bound=0.0), 1), 'cov_factor': IndependentConstraint(Real(), 2), 'loc': IndependentConstraint(Real(), 1)}
- property covariance_matrix
- entropy()[source]
Returns entropy of distribution, batched over batch_shape.
- Returns:
Tensor of shape batch_shape.
- expand(batch_shape, _instance=None)[source]
Returns a new distribution instance (or populates an existing instance provided by a derived class) with batch dimensions expanded to batch_shape. This method calls
expandon the distribution’s parameters. As such, this does not allocate new memory for the expanded distribution instance. Additionally, this does not repeat any args checking or parameter broadcasting in __init__.py, when an instance is first created.- Args:
batch_shape (torch.Size): the desired expanded size. _instance: new instance provided by subclasses that
need to override .expand.
- Returns:
New distribution instance with batch dimensions expanded to batch_size.
- has_rsample = True
- log_prob(value)[source]
Returns the log of the probability density/mass function evaluated at value.
- Args:
value (Tensor):
- property mean
Returns the mean of the distribution.
- property mode
Returns the mode of the distribution.
- property precision_matrix
- rsample(sample_shape: Size | List[int] | Tuple[int, ...] = ()) Tensor[source]
Generates a sample_shape shaped reparameterized sample or sample_shape shaped batch of reparameterized samples if the distribution parameters are batched.
- property scale_tril
- support = IndependentConstraint(Real(), 1)
- property variance
Returns the variance of the distribution.
- class skwdro.distributions.LowerCholeskyTransform(cache_size=0)[source]
Bases:
TransformTransform from unconstrained matrices to lower-triangular matrices with nonnegative diagonal entries.
This is useful for parameterizing positive definite matrices in terms of their Cholesky factorization.
- codomain: Constraint = LowerCholesky()
- domain: Constraint = IndependentConstraint(Real(), 2)
- class skwdro.distributions.MixtureSameFamily(mixture_distribution, component_distribution, validate_args=None)[source]
Bases:
DistributionThe MixtureSameFamily distribution implements a (batch of) mixture distribution where all component are from different parameterizations of the same distribution type. It is parameterized by a Categorical “selecting distribution” (over k component) and a component distribution, i.e., a Distribution with a rightmost batch shape (equal to [k]) which indexes each (batch of) component.
Examples:
>>> # xdoctest: +SKIP("undefined vars") >>> # Construct Gaussian Mixture Model in 1D consisting of 5 equally >>> # weighted normal distributions >>> mix = D.Categorical(torch.ones(5,)) >>> comp = D.Normal(torch.randn(5,), torch.rand(5,)) >>> gmm = MixtureSameFamily(mix, comp) >>> # Construct Gaussian Mixture Model in 2D consisting of 5 equally >>> # weighted bivariate normal distributions >>> mix = D.Categorical(torch.ones(5,)) >>> comp = D.Independent(D.Normal( ... torch.randn(5,2), torch.rand(5,2)), 1) >>> gmm = MixtureSameFamily(mix, comp) >>> # Construct a batch of 3 Gaussian Mixture Models in 2D each >>> # consisting of 5 random weighted bivariate normal distributions >>> mix = D.Categorical(torch.rand(3,5)) >>> comp = D.Independent(D.Normal( ... torch.randn(3,5,2), torch.rand(3,5,2)), 1) >>> gmm = MixtureSameFamily(mix, comp)
- Args:
- mixture_distribution: torch.distributions.Categorical-like
instance. Manages the probability of selecting component. The number of categories must match the rightmost batch dimension of the component_distribution. Must have either scalar batch_shape or batch_shape matching component_distribution.batch_shape[:-1]
- component_distribution: torch.distributions.Distribution-like
instance. Right-most batch dimension indexes component.
- cdf(x)[source]
Returns the cumulative density/mass function evaluated at value.
- Args:
value (Tensor):
- property component_distribution
- expand(batch_shape, _instance=None)[source]
Returns a new distribution instance (or populates an existing instance provided by a derived class) with batch dimensions expanded to batch_shape. This method calls
expandon the distribution’s parameters. As such, this does not allocate new memory for the expanded distribution instance. Additionally, this does not repeat any args checking or parameter broadcasting in __init__.py, when an instance is first created.- Args:
batch_shape (torch.Size): the desired expanded size. _instance: new instance provided by subclasses that
need to override .expand.
- Returns:
New distribution instance with batch dimensions expanded to batch_size.
- has_rsample = False
- log_prob(x)[source]
Returns the log of the probability density/mass function evaluated at value.
- Args:
value (Tensor):
- property mean
Returns the mean of the distribution.
- property mixture_distribution
- sample(sample_shape=())[source]
Generates a sample_shape shaped sample or sample_shape shaped batch of samples if the distribution parameters are batched.
- property support
Returns a
Constraintobject representing this distribution’s support.
- property variance
Returns the variance of the distribution.
- class skwdro.distributions.Multinomial(total_count=1, probs=None, logits=None, validate_args=None)[source]
Bases:
DistributionCreates a Multinomial distribution parameterized by
total_countand eitherprobsorlogits(but not both). The innermost dimension ofprobsindexes over categories. All other dimensions index over batches.Note that
total_countneed not be specified if onlylog_prob()is called (see example below)Note
The probs argument must be non-negative, finite and have a non-zero sum, and it will be normalized to sum to 1 along the last dimension.
probswill return this normalized value. The logits argument will be interpreted as unnormalized log probabilities and can therefore be any real number. It will likewise be normalized so that the resulting probabilities sum to 1 along the last dimension.logitswill return this normalized value.sample()requires a single shared total_count for all parameters and samples.log_prob()allows different total_count for each parameter and sample.
Example:
>>> # xdoctest: +SKIP("FIXME: found invalid values") >>> m = Multinomial(100, torch.tensor([ 1., 1., 1., 1.])) >>> x = m.sample() # equal probability of 0, 1, 2, 3 tensor([ 21., 24., 30., 25.]) >>> Multinomial(probs=torch.tensor([1., 1., 1., 1.])).log_prob(x) tensor([-4.1338])
- Args:
total_count (int): number of trials probs (Tensor): event probabilities logits (Tensor): event log probabilities (unnormalized)
- arg_constraints = {'logits': IndependentConstraint(Real(), 1), 'probs': Simplex()}
- entropy()[source]
Returns entropy of distribution, batched over batch_shape.
- Returns:
Tensor of shape batch_shape.
- expand(batch_shape, _instance=None)[source]
Returns a new distribution instance (or populates an existing instance provided by a derived class) with batch dimensions expanded to batch_shape. This method calls
expandon the distribution’s parameters. As such, this does not allocate new memory for the expanded distribution instance. Additionally, this does not repeat any args checking or parameter broadcasting in __init__.py, when an instance is first created.- Args:
batch_shape (torch.Size): the desired expanded size. _instance: new instance provided by subclasses that
need to override .expand.
- Returns:
New distribution instance with batch dimensions expanded to batch_size.
- log_prob(value)[source]
Returns the log of the probability density/mass function evaluated at value.
- Args:
value (Tensor):
- property logits
- property mean
Returns the mean of the distribution.
- property param_shape
- property probs
- sample(sample_shape=())[source]
Generates a sample_shape shaped sample or sample_shape shaped batch of samples if the distribution parameters are batched.
- property support
Returns a
Constraintobject representing this distribution’s support.
- property variance
Returns the variance of the distribution.
- class skwdro.distributions.MultivariateNormal(loc, covariance_matrix=None, precision_matrix=None, scale_tril=None, validate_args=None)[source]
Bases:
DistributionCreates a multivariate normal (also called Gaussian) distribution parameterized by a mean vector and a covariance matrix.
The multivariate normal distribution can be parameterized either in terms of a positive definite covariance matrix
 or a positive definite precision matrix
or a positive definite precision matrix 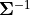 or a lower-triangular matrix
or a lower-triangular matrix  with positive-valued
diagonal entries, such that
with positive-valued
diagonal entries, such that
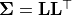 . This triangular matrix
can be obtained via e.g. Cholesky decomposition of the covariance.
. This triangular matrix
can be obtained via e.g. Cholesky decomposition of the covariance.Example:
>>> # xdoctest: +REQUIRES(env:TORCH_DOCTEST_LAPACK) >>> # xdoctest: +IGNORE_WANT("non-deterministic") >>> m = MultivariateNormal(torch.zeros(2), torch.eye(2)) >>> m.sample() # normally distributed with mean=`[0,0]` and covariance_matrix=`I` tensor([-0.2102, -0.5429])
- Args:
loc (Tensor): mean of the distribution covariance_matrix (Tensor): positive-definite covariance matrix precision_matrix (Tensor): positive-definite precision matrix scale_tril (Tensor): lower-triangular factor of covariance, with positive-valued diagonal
- Note:
Only one of
covariance_matrixorprecision_matrixorscale_trilcan be specified.Using
scale_trilwill be more efficient: all computations internally are based onscale_tril. Ifcovariance_matrixorprecision_matrixis passed instead, it is only used to compute the corresponding lower triangular matrices using a Cholesky decomposition.
- arg_constraints = {'covariance_matrix': PositiveDefinite(), 'loc': IndependentConstraint(Real(), 1), 'precision_matrix': PositiveDefinite(), 'scale_tril': LowerCholesky()}
- property covariance_matrix
- entropy()[source]
Returns entropy of distribution, batched over batch_shape.
- Returns:
Tensor of shape batch_shape.
- expand(batch_shape, _instance=None)[source]
Returns a new distribution instance (or populates an existing instance provided by a derived class) with batch dimensions expanded to batch_shape. This method calls
expandon the distribution’s parameters. As such, this does not allocate new memory for the expanded distribution instance. Additionally, this does not repeat any args checking or parameter broadcasting in __init__.py, when an instance is first created.- Args:
batch_shape (torch.Size): the desired expanded size. _instance: new instance provided by subclasses that
need to override .expand.
- Returns:
New distribution instance with batch dimensions expanded to batch_size.
- has_rsample = True
- log_prob(value)[source]
Returns the log of the probability density/mass function evaluated at value.
- Args:
value (Tensor):
- property mean
Returns the mean of the distribution.
- property mode
Returns the mode of the distribution.
- property precision_matrix
- rsample(sample_shape: Size | List[int] | Tuple[int, ...] = ()) Tensor[source]
Generates a sample_shape shaped reparameterized sample or sample_shape shaped batch of reparameterized samples if the distribution parameters are batched.
- property scale_tril
- support = IndependentConstraint(Real(), 1)
- property variance
Returns the variance of the distribution.
- class skwdro.distributions.NegativeBinomial(total_count, probs=None, logits=None, validate_args=None)[source]
Bases:
DistributionCreates a Negative Binomial distribution, i.e. distribution of the number of successful independent and identical Bernoulli trials before
total_countfailures are achieved. The probability of success of each Bernoulli trial isprobs.- Args:
- total_count (float or Tensor): non-negative number of negative Bernoulli
trials to stop, although the distribution is still valid for real valued count
probs (Tensor): Event probabilities of success in the half open interval [0, 1) logits (Tensor): Event log-odds for probabilities of success
- arg_constraints = {'logits': Real(), 'probs': HalfOpenInterval(lower_bound=0.0, upper_bound=1.0), 'total_count': GreaterThanEq(lower_bound=0)}
- expand(batch_shape, _instance=None)[source]
Returns a new distribution instance (or populates an existing instance provided by a derived class) with batch dimensions expanded to batch_shape. This method calls
expandon the distribution’s parameters. As such, this does not allocate new memory for the expanded distribution instance. Additionally, this does not repeat any args checking or parameter broadcasting in __init__.py, when an instance is first created.- Args:
batch_shape (torch.Size): the desired expanded size. _instance: new instance provided by subclasses that
need to override .expand.
- Returns:
New distribution instance with batch dimensions expanded to batch_size.
- log_prob(value)[source]
Returns the log of the probability density/mass function evaluated at value.
- Args:
value (Tensor):
- property logits
- property mean
Returns the mean of the distribution.
- property mode
Returns the mode of the distribution.
- property param_shape
- property probs
- sample(sample_shape=())[source]
Generates a sample_shape shaped sample or sample_shape shaped batch of samples if the distribution parameters are batched.
- support = IntegerGreaterThan(lower_bound=0)
- property variance
Returns the variance of the distribution.
- class skwdro.distributions.Normal(loc, scale, validate_args=None)[source]
Bases:
ExponentialFamilyCreates a normal (also called Gaussian) distribution parameterized by
locandscale.Example:
>>> # xdoctest: +IGNORE_WANT("non-deterministic") >>> m = Normal(torch.tensor([0.0]), torch.tensor([1.0])) >>> m.sample() # normally distributed with loc=0 and scale=1 tensor([ 0.1046])
- Args:
loc (float or Tensor): mean of the distribution (often referred to as mu) scale (float or Tensor): standard deviation of the distribution
(often referred to as sigma)
- arg_constraints = {'loc': Real(), 'scale': GreaterThan(lower_bound=0.0)}
- cdf(value)[source]
Returns the cumulative density/mass function evaluated at value.
- Args:
value (Tensor):
- expand(batch_shape, _instance=None)[source]
Returns a new distribution instance (or populates an existing instance provided by a derived class) with batch dimensions expanded to batch_shape. This method calls
expandon the distribution’s parameters. As such, this does not allocate new memory for the expanded distribution instance. Additionally, this does not repeat any args checking or parameter broadcasting in __init__.py, when an instance is first created.- Args:
batch_shape (torch.Size): the desired expanded size. _instance: new instance provided by subclasses that
need to override .expand.
- Returns:
New distribution instance with batch dimensions expanded to batch_size.
- has_rsample = True
- icdf(value)[source]
Returns the inverse cumulative density/mass function evaluated at value.
- Args:
value (Tensor):
- log_prob(value)[source]
Returns the log of the probability density/mass function evaluated at value.
- Args:
value (Tensor):
- property mean
Returns the mean of the distribution.
- property mode
Returns the mode of the distribution.
- rsample(sample_shape: Size | List[int] | Tuple[int, ...] = ()) Tensor[source]
Generates a sample_shape shaped reparameterized sample or sample_shape shaped batch of reparameterized samples if the distribution parameters are batched.
- sample(sample_shape=())[source]
Generates a sample_shape shaped sample or sample_shape shaped batch of samples if the distribution parameters are batched.
- property stddev
Returns the standard deviation of the distribution.
- support = Real()
- property variance
Returns the variance of the distribution.
- class skwdro.distributions.OneHotCategorical(probs=None, logits=None, validate_args=None)[source]
Bases:
DistributionCreates a one-hot categorical distribution parameterized by
probsorlogits.Samples are one-hot coded vectors of size
probs.size(-1).Note
The probs argument must be non-negative, finite and have a non-zero sum, and it will be normalized to sum to 1 along the last dimension.
probswill return this normalized value. The logits argument will be interpreted as unnormalized log probabilities and can therefore be any real number. It will likewise be normalized so that the resulting probabilities sum to 1 along the last dimension.logitswill return this normalized value.See also:
torch.distributions.Categorical()for specifications ofprobsandlogits.Example:
>>> # xdoctest: +IGNORE_WANT("non-deterministic") >>> m = OneHotCategorical(torch.tensor([ 0.25, 0.25, 0.25, 0.25 ])) >>> m.sample() # equal probability of 0, 1, 2, 3 tensor([ 0., 0., 0., 1.])
- Args:
probs (Tensor): event probabilities logits (Tensor): event log probabilities (unnormalized)
- arg_constraints = {'logits': IndependentConstraint(Real(), 1), 'probs': Simplex()}
- entropy()[source]
Returns entropy of distribution, batched over batch_shape.
- Returns:
Tensor of shape batch_shape.
- enumerate_support(expand=True)[source]
Returns tensor containing all values supported by a discrete distribution. The result will enumerate over dimension 0, so the shape of the result will be (cardinality,) + batch_shape + event_shape (where event_shape = () for univariate distributions).
Note that this enumerates over all batched tensors in lock-step [[0, 0], [1, 1], …]. With expand=False, enumeration happens along dim 0, but with the remaining batch dimensions being singleton dimensions, [[0], [1], ...
To iterate over the full Cartesian product use itertools.product(m.enumerate_support()).
- Args:
- expand (bool): whether to expand the support over the
batch dims to match the distribution’s batch_shape.
- Returns:
Tensor iterating over dimension 0.
- expand(batch_shape, _instance=None)[source]
Returns a new distribution instance (or populates an existing instance provided by a derived class) with batch dimensions expanded to batch_shape. This method calls
expandon the distribution’s parameters. As such, this does not allocate new memory for the expanded distribution instance. Additionally, this does not repeat any args checking or parameter broadcasting in __init__.py, when an instance is first created.- Args:
batch_shape (torch.Size): the desired expanded size. _instance: new instance provided by subclasses that
need to override .expand.
- Returns:
New distribution instance with batch dimensions expanded to batch_size.
- has_enumerate_support = True
- log_prob(value)[source]
Returns the log of the probability density/mass function evaluated at value.
- Args:
value (Tensor):
- property logits
- property mean
Returns the mean of the distribution.
- property mode
Returns the mode of the distribution.
- property param_shape
- property probs
- sample(sample_shape=())[source]
Generates a sample_shape shaped sample or sample_shape shaped batch of samples if the distribution parameters are batched.
- support = OneHot()
- property variance
Returns the variance of the distribution.
- class skwdro.distributions.OneHotCategoricalStraightThrough(probs=None, logits=None, validate_args=None)[source]
Bases:
OneHotCategoricalCreates a reparameterizable
OneHotCategoricaldistribution based on the straight- through gradient estimator from [1].[1] Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation (Bengio et al., 2013)
- has_rsample = True
- class skwdro.distributions.Pareto(scale, alpha, validate_args=None)[source]
Bases:
TransformedDistributionSamples from a Pareto Type 1 distribution.
Example:
>>> # xdoctest: +IGNORE_WANT("non-deterministic") >>> m = Pareto(torch.tensor([1.0]), torch.tensor([1.0])) >>> m.sample() # sample from a Pareto distribution with scale=1 and alpha=1 tensor([ 1.5623])
- Args:
scale (float or Tensor): Scale parameter of the distribution alpha (float or Tensor): Shape parameter of the distribution
- arg_constraints: Dict[str, constraints.Constraint] = {'alpha': GreaterThan(lower_bound=0.0), 'scale': GreaterThan(lower_bound=0.0)}
- entropy()[source]
Returns entropy of distribution, batched over batch_shape.
- Returns:
Tensor of shape batch_shape.
- expand(batch_shape, _instance=None)[source]
Returns a new distribution instance (or populates an existing instance provided by a derived class) with batch dimensions expanded to batch_shape. This method calls
expandon the distribution’s parameters. As such, this does not allocate new memory for the expanded distribution instance. Additionally, this does not repeat any args checking or parameter broadcasting in __init__.py, when an instance is first created.- Args:
batch_shape (torch.Size): the desired expanded size. _instance: new instance provided by subclasses that
need to override .expand.
- Returns:
New distribution instance with batch dimensions expanded to batch_size.
- property mean
Returns the mean of the distribution.
- property mode
Returns the mode of the distribution.
- property support
Returns a
Constraintobject representing this distribution’s support.
- property variance
Returns the variance of the distribution.
- class skwdro.distributions.Poisson(rate, validate_args=None)[source]
Bases:
ExponentialFamilyCreates a Poisson distribution parameterized by
rate, the rate parameter.Samples are nonnegative integers, with a pmf given by
Example:
>>> # xdoctest: +SKIP("poisson_cpu not implemented for 'Long'") >>> m = Poisson(torch.tensor([4])) >>> m.sample() tensor([ 3.])
- Args:
rate (Number, Tensor): the rate parameter
- arg_constraints = {'rate': GreaterThanEq(lower_bound=0.0)}
- expand(batch_shape, _instance=None)[source]
Returns a new distribution instance (or populates an existing instance provided by a derived class) with batch dimensions expanded to batch_shape. This method calls
expandon the distribution’s parameters. As such, this does not allocate new memory for the expanded distribution instance. Additionally, this does not repeat any args checking or parameter broadcasting in __init__.py, when an instance is first created.- Args:
batch_shape (torch.Size): the desired expanded size. _instance: new instance provided by subclasses that
need to override .expand.
- Returns:
New distribution instance with batch dimensions expanded to batch_size.
- log_prob(value)[source]
Returns the log of the probability density/mass function evaluated at value.
- Args:
value (Tensor):
- property mean
Returns the mean of the distribution.
- property mode
Returns the mode of the distribution.
- sample(sample_shape=())[source]
Generates a sample_shape shaped sample or sample_shape shaped batch of samples if the distribution parameters are batched.
- support = IntegerGreaterThan(lower_bound=0)
- property variance
Returns the variance of the distribution.
- class skwdro.distributions.PositiveDefiniteTransform(cache_size=0)[source]
Bases:
TransformTransform from unconstrained matrices to positive-definite matrices.
- codomain: Constraint = PositiveDefinite()
- domain: Constraint = IndependentConstraint(Real(), 2)
- class skwdro.distributions.PowerTransform(exponent, cache_size=0)[source]
Bases:
TransformTransform via the mapping
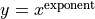 .
.- bijective = True
- codomain: Constraint = GreaterThan(lower_bound=0.0)
- domain: Constraint = GreaterThan(lower_bound=0.0)
- forward_shape(shape)[source]
Infers the shape of the forward computation, given the input shape. Defaults to preserving shape.
- inverse_shape(shape)[source]
Infers the shapes of the inverse computation, given the output shape. Defaults to preserving shape.
- log_abs_det_jacobian(x, y)[source]
Computes the log det jacobian log |dy/dx| given input and output.
- property sign
Returns the sign of the determinant of the Jacobian, if applicable. In general this only makes sense for bijective transforms.
- class skwdro.distributions.RelaxedBernoulli(temperature, probs=None, logits=None, validate_args=None)[source]
Bases:
TransformedDistributionCreates a RelaxedBernoulli distribution, parametrized by
temperature, and eitherprobsorlogits(but not both). This is a relaxed version of the Bernoulli distribution, so the values are in (0, 1), and has reparametrizable samples.Example:
>>> # xdoctest: +IGNORE_WANT("non-deterministic") >>> m = RelaxedBernoulli(torch.tensor([2.2]), ... torch.tensor([0.1, 0.2, 0.3, 0.99])) >>> m.sample() tensor([ 0.2951, 0.3442, 0.8918, 0.9021])
- Args:
temperature (Tensor): relaxation temperature probs (Number, Tensor): the probability of sampling 1 logits (Number, Tensor): the log-odds of sampling 1
- arg_constraints: Dict[str, constraints.Constraint] = {'logits': Real(), 'probs': Interval(lower_bound=0.0, upper_bound=1.0)}
- expand(batch_shape, _instance=None)[source]
Returns a new distribution instance (or populates an existing instance provided by a derived class) with batch dimensions expanded to batch_shape. This method calls
expandon the distribution’s parameters. As such, this does not allocate new memory for the expanded distribution instance. Additionally, this does not repeat any args checking or parameter broadcasting in __init__.py, when an instance is first created.- Args:
batch_shape (torch.Size): the desired expanded size. _instance: new instance provided by subclasses that
need to override .expand.
- Returns:
New distribution instance with batch dimensions expanded to batch_size.
- has_rsample = True
- property logits
- property probs
- support = Interval(lower_bound=0.0, upper_bound=1.0)
- property temperature
- class skwdro.distributions.RelaxedOneHotCategorical(temperature, probs=None, logits=None, validate_args=None)[source]
Bases:
TransformedDistributionCreates a RelaxedOneHotCategorical distribution parametrized by
temperature, and eitherprobsorlogits. This is a relaxed version of theOneHotCategoricaldistribution, so its samples are on simplex, and are reparametrizable.Example:
>>> # xdoctest: +IGNORE_WANT("non-deterministic") >>> m = RelaxedOneHotCategorical(torch.tensor([2.2]), ... torch.tensor([0.1, 0.2, 0.3, 0.4])) >>> m.sample() tensor([ 0.1294, 0.2324, 0.3859, 0.2523])
- Args:
temperature (Tensor): relaxation temperature probs (Tensor): event probabilities logits (Tensor): unnormalized log probability for each event
- arg_constraints: Dict[str, constraints.Constraint] = {'logits': IndependentConstraint(Real(), 1), 'probs': Simplex()}
- expand(batch_shape, _instance=None)[source]
Returns a new distribution instance (or populates an existing instance provided by a derived class) with batch dimensions expanded to batch_shape. This method calls
expandon the distribution’s parameters. As such, this does not allocate new memory for the expanded distribution instance. Additionally, this does not repeat any args checking or parameter broadcasting in __init__.py, when an instance is first created.- Args:
batch_shape (torch.Size): the desired expanded size. _instance: new instance provided by subclasses that
need to override .expand.
- Returns:
New distribution instance with batch dimensions expanded to batch_size.
- has_rsample = True
- property logits
- property probs
- support = Simplex()
- property temperature
- class skwdro.distributions.ReshapeTransform(in_shape, out_shape, cache_size=0)[source]
Bases:
TransformUnit Jacobian transform to reshape the rightmost part of a tensor.
Note that
in_shapeandout_shapemust have the same number of elements, just as fortorch.Tensor.reshape().- Arguments:
in_shape (torch.Size): The input event shape. out_shape (torch.Size): The output event shape.
- bijective = True
- property codomain
- property domain
- forward_shape(shape)[source]
Infers the shape of the forward computation, given the input shape. Defaults to preserving shape.
- inverse_shape(shape)[source]
Infers the shapes of the inverse computation, given the output shape. Defaults to preserving shape.
- class skwdro.distributions.SigmoidTransform(cache_size=0)[source]
Bases:
TransformTransform via the mapping
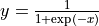 and
and 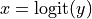 .
.- bijective = True
- codomain: Constraint = Interval(lower_bound=0.0, upper_bound=1.0)
- domain: Constraint = Real()
- log_abs_det_jacobian(x, y)[source]
Computes the log det jacobian log |dy/dx| given input and output.
- sign = 1
- class skwdro.distributions.SoftmaxTransform(cache_size=0)[source]
Bases:
TransformTransform from unconstrained space to the simplex via
then
normalizing.This is not bijective and cannot be used for HMC. However this acts mostly coordinate-wise (except for the final normalization), and thus is appropriate for coordinate-wise optimization algorithms.
- codomain: Constraint = Simplex()
- domain: Constraint = IndependentConstraint(Real(), 1)
- class skwdro.distributions.SoftplusTransform(cache_size=0)[source]
Bases:
TransformTransform via the mapping
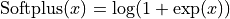 .
The implementation reverts to the linear function when
.
The implementation reverts to the linear function when 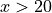 .
.- bijective = True
- codomain: Constraint = GreaterThan(lower_bound=0.0)
- domain: Constraint = Real()
- log_abs_det_jacobian(x, y)[source]
Computes the log det jacobian log |dy/dx| given input and output.
- sign = 1
- class skwdro.distributions.StackTransform(tseq, dim=0, cache_size=0)[source]
Bases:
TransformTransform functor that applies a sequence of transforms tseq component-wise to each submatrix at dim in a way compatible with
torch.stack().Example:
x = torch.stack([torch.range(1, 10), torch.range(1, 10)], dim=1) t = StackTransform([ExpTransform(), identity_transform], dim=1) y = t(x)
- property bijective
bool(x) -> bool
Returns True when the argument x is true, False otherwise. The builtins True and False are the only two instances of the class bool. The class bool is a subclass of the class int, and cannot be subclassed.
- property codomain
- property domain
- class skwdro.distributions.StickBreakingTransform(cache_size=0)[source]
Bases:
TransformTransform from unconstrained space to the simplex of one additional dimension via a stick-breaking process.
This transform arises as an iterated sigmoid transform in a stick-breaking construction of the Dirichlet distribution: the first logit is transformed via sigmoid to the first probability and the probability of everything else, and then the process recurses.
This is bijective and appropriate for use in HMC; however it mixes coordinates together and is less appropriate for optimization.
- bijective = True
- codomain: Constraint = Simplex()
- domain: Constraint = IndependentConstraint(Real(), 1)
- forward_shape(shape)[source]
Infers the shape of the forward computation, given the input shape. Defaults to preserving shape.
- class skwdro.distributions.StudentT(df, loc=0.0, scale=1.0, validate_args=None)[source]
Bases:
DistributionCreates a Student’s t-distribution parameterized by degree of freedom
df, meanlocand scalescale.Example:
>>> # xdoctest: +IGNORE_WANT("non-deterministic") >>> m = StudentT(torch.tensor([2.0])) >>> m.sample() # Student's t-distributed with degrees of freedom=2 tensor([ 0.1046])
- Args:
df (float or Tensor): degrees of freedom loc (float or Tensor): mean of the distribution scale (float or Tensor): scale of the distribution
- arg_constraints = {'df': GreaterThan(lower_bound=0.0), 'loc': Real(), 'scale': GreaterThan(lower_bound=0.0)}
- entropy()[source]
Returns entropy of distribution, batched over batch_shape.
- Returns:
Tensor of shape batch_shape.
- expand(batch_shape, _instance=None)[source]
Returns a new distribution instance (or populates an existing instance provided by a derived class) with batch dimensions expanded to batch_shape. This method calls
expandon the distribution’s parameters. As such, this does not allocate new memory for the expanded distribution instance. Additionally, this does not repeat any args checking or parameter broadcasting in __init__.py, when an instance is first created.- Args:
batch_shape (torch.Size): the desired expanded size. _instance: new instance provided by subclasses that
need to override .expand.
- Returns:
New distribution instance with batch dimensions expanded to batch_size.
- has_rsample = True
- log_prob(value)[source]
Returns the log of the probability density/mass function evaluated at value.
- Args:
value (Tensor):
- property mean
Returns the mean of the distribution.
- property mode
Returns the mode of the distribution.
- rsample(sample_shape: Size | List[int] | Tuple[int, ...] = ()) Tensor[source]
Generates a sample_shape shaped reparameterized sample or sample_shape shaped batch of reparameterized samples if the distribution parameters are batched.
- support = Real()
- property variance
Returns the variance of the distribution.
- class skwdro.distributions.TanhTransform(cache_size=0)[source]
Bases:
TransformTransform via the mapping
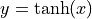 .
.It is equivalent to
` ComposeTransform([AffineTransform(0., 2.), SigmoidTransform(), AffineTransform(-1., 2.)]) `However this might not be numerically stable, thus it is recommended to use TanhTransform instead.Note that one should use cache_size=1 when it comes to NaN/Inf values.
- bijective = True
- codomain: Constraint = Interval(lower_bound=-1.0, upper_bound=1.0)
- domain: Constraint = Real()
- log_abs_det_jacobian(x, y)[source]
Computes the log det jacobian log |dy/dx| given input and output.
- sign = 1
- class skwdro.distributions.Transform(cache_size=0)[source]
Bases:
objectAbstract class for invertable transformations with computable log det jacobians. They are primarily used in
torch.distributions.TransformedDistribution.Caching is useful for transforms whose inverses are either expensive or numerically unstable. Note that care must be taken with memoized values since the autograd graph may be reversed. For example while the following works with or without caching:
y = t(x) t.log_abs_det_jacobian(x, y).backward() # x will receive gradients.
However the following will error when caching due to dependency reversal:
y = t(x) z = t.inv(y) grad(z.sum(), [y]) # error because z is x
Derived classes should implement one or both of
_call()or_inverse(). Derived classes that set bijective=True should also implementlog_abs_det_jacobian().- Args:
- cache_size (int): Size of cache. If zero, no caching is done. If one,
the latest single value is cached. Only 0 and 1 are supported.
- Attributes:
- domain (
Constraint): The constraint representing valid inputs to this transform.
- codomain (
Constraint): The constraint representing valid outputs to this transform which are inputs to the inverse transform.
- bijective (bool): Whether this transform is bijective. A transform
tis bijective ifft.inv(t(x)) == xandt(t.inv(y)) == yfor everyxin the domain andyin the codomain. Transforms that are not bijective should at least maintain the weaker pseudoinverse propertiest(t.inv(t(x)) == t(x)andt.inv(t(t.inv(y))) == t.inv(y).- sign (int or Tensor): For bijective univariate transforms, this
should be +1 or -1 depending on whether transform is monotone increasing or decreasing.
- domain (
- bijective = False
- codomain: Constraint
- domain: Constraint
- property event_dim
- forward_shape(shape)[source]
Infers the shape of the forward computation, given the input shape. Defaults to preserving shape.
- inverse_shape(shape)[source]
Infers the shapes of the inverse computation, given the output shape. Defaults to preserving shape.
- log_abs_det_jacobian(x, y)[source]
Computes the log det jacobian log |dy/dx| given input and output.
- property sign
Returns the sign of the determinant of the Jacobian, if applicable. In general this only makes sense for bijective transforms.
- class skwdro.distributions.TransformedDistribution(base_distribution, transforms, validate_args=None)[source]
Bases:
DistributionExtension of the Distribution class, which applies a sequence of Transforms to a base distribution. Let f be the composition of transforms applied:
X ~ BaseDistribution Y = f(X) ~ TransformedDistribution(BaseDistribution, f) log p(Y) = log p(X) + log |det (dX/dY)|
Note that the
.event_shapeof aTransformedDistributionis the maximum shape of its base distribution and its transforms, since transforms can introduce correlations among events.An example for the usage of
TransformedDistributionwould be:# Building a Logistic Distribution # X ~ Uniform(0, 1) # f = a + b * logit(X) # Y ~ f(X) ~ Logistic(a, b) base_distribution = Uniform(0, 1) transforms = [SigmoidTransform().inv, AffineTransform(loc=a, scale=b)] logistic = TransformedDistribution(base_distribution, transforms)
For more examples, please look at the implementations of
Gumbel,HalfCauchy,HalfNormal,LogNormal,Pareto,Weibull,RelaxedBernoulliandRelaxedOneHotCategorical- cdf(value)[source]
Computes the cumulative distribution function by inverting the transform(s) and computing the score of the base distribution.
- expand(batch_shape, _instance=None)[source]
Returns a new distribution instance (or populates an existing instance provided by a derived class) with batch dimensions expanded to batch_shape. This method calls
expandon the distribution’s parameters. As such, this does not allocate new memory for the expanded distribution instance. Additionally, this does not repeat any args checking or parameter broadcasting in __init__.py, when an instance is first created.- Args:
batch_shape (torch.Size): the desired expanded size. _instance: new instance provided by subclasses that
need to override .expand.
- Returns:
New distribution instance with batch dimensions expanded to batch_size.
- property has_rsample
bool(x) -> bool
Returns True when the argument x is true, False otherwise. The builtins True and False are the only two instances of the class bool. The class bool is a subclass of the class int, and cannot be subclassed.
- icdf(value)[source]
Computes the inverse cumulative distribution function using transform(s) and computing the score of the base distribution.
- log_prob(value)[source]
Scores the sample by inverting the transform(s) and computing the score using the score of the base distribution and the log abs det jacobian.
- rsample(sample_shape: Size | List[int] | Tuple[int, ...] = ()) Tensor[source]
Generates a sample_shape shaped reparameterized sample or sample_shape shaped batch of reparameterized samples if the distribution parameters are batched. Samples first from base distribution and applies transform() for every transform in the list.
- sample(sample_shape=())[source]
Generates a sample_shape shaped sample or sample_shape shaped batch of samples if the distribution parameters are batched. Samples first from base distribution and applies transform() for every transform in the list.
- property support
Returns a
Constraintobject representing this distribution’s support.
- class skwdro.distributions.Uniform(low, high, validate_args=None)[source]
Bases:
DistributionGenerates uniformly distributed random samples from the half-open interval
[low, high).Example:
>>> m = Uniform(torch.tensor([0.0]), torch.tensor([5.0])) >>> m.sample() # uniformly distributed in the range [0.0, 5.0) >>> # xdoctest: +SKIP tensor([ 2.3418])
- Args:
low (float or Tensor): lower range (inclusive). high (float or Tensor): upper range (exclusive).
- arg_constraints = {'high': Dependent(), 'low': Dependent()}
- cdf(value)[source]
Returns the cumulative density/mass function evaluated at value.
- Args:
value (Tensor):
- entropy()[source]
Returns entropy of distribution, batched over batch_shape.
- Returns:
Tensor of shape batch_shape.
- expand(batch_shape, _instance=None)[source]
Returns a new distribution instance (or populates an existing instance provided by a derived class) with batch dimensions expanded to batch_shape. This method calls
expandon the distribution’s parameters. As such, this does not allocate new memory for the expanded distribution instance. Additionally, this does not repeat any args checking or parameter broadcasting in __init__.py, when an instance is first created.- Args:
batch_shape (torch.Size): the desired expanded size. _instance: new instance provided by subclasses that
need to override .expand.
- Returns:
New distribution instance with batch dimensions expanded to batch_size.
- has_rsample = True
- icdf(value)[source]
Returns the inverse cumulative density/mass function evaluated at value.
- Args:
value (Tensor):
- log_prob(value)[source]
Returns the log of the probability density/mass function evaluated at value.
- Args:
value (Tensor):
- property mean
Returns the mean of the distribution.
- property mode
Returns the mode of the distribution.
- rsample(sample_shape: Size | List[int] | Tuple[int, ...] = ()) Tensor[source]
Generates a sample_shape shaped reparameterized sample or sample_shape shaped batch of reparameterized samples if the distribution parameters are batched.
- property stddev
Returns the standard deviation of the distribution.
- property support
Returns a
Constraintobject representing this distribution’s support.
- property variance
Returns the variance of the distribution.
- class skwdro.distributions.VonMises(loc, concentration, validate_args=None)[source]
Bases:
DistributionA circular von Mises distribution.
This implementation uses polar coordinates. The
locandvalueargs can be any real number (to facilitate unconstrained optimization), but are interpreted as angles modulo 2 pi.- Example::
>>> # xdoctest: +IGNORE_WANT("non-deterministic") >>> m = VonMises(torch.tensor([1.0]), torch.tensor([1.0])) >>> m.sample() # von Mises distributed with loc=1 and concentration=1 tensor([1.9777])
- Parameters:
loc (torch.Tensor) – an angle in radians.
concentration (torch.Tensor) – concentration parameter
- arg_constraints = {'concentration': GreaterThan(lower_bound=0.0), 'loc': Real()}
- expand(batch_shape)[source]
Returns a new distribution instance (or populates an existing instance provided by a derived class) with batch dimensions expanded to batch_shape. This method calls
expandon the distribution’s parameters. As such, this does not allocate new memory for the expanded distribution instance. Additionally, this does not repeat any args checking or parameter broadcasting in __init__.py, when an instance is first created.- Args:
batch_shape (torch.Size): the desired expanded size. _instance: new instance provided by subclasses that
need to override .expand.
- Returns:
New distribution instance with batch dimensions expanded to batch_size.
- has_rsample = False
- log_prob(value)[source]
Returns the log of the probability density/mass function evaluated at value.
- Args:
value (Tensor):
- property mean
The provided mean is the circular one.
- property mode
Returns the mode of the distribution.
- sample(sample_shape=())[source]
The sampling algorithm for the von Mises distribution is based on the following paper: D.J. Best and N.I. Fisher, “Efficient simulation of the von Mises distribution.” Applied Statistics (1979): 152-157.
Sampling is always done in double precision internally to avoid a hang in _rejection_sample() for small values of the concentration, which starts to happen for single precision around 1e-4 (see issue #88443).
- support = Real()
- property variance
The provided variance is the circular one.
- class skwdro.distributions.Weibull(scale, concentration, validate_args=None)[source]
Bases:
TransformedDistributionSamples from a two-parameter Weibull distribution.
Example:
>>> # xdoctest: +IGNORE_WANT("non-deterministic") >>> m = Weibull(torch.tensor([1.0]), torch.tensor([1.0])) >>> m.sample() # sample from a Weibull distribution with scale=1, concentration=1 tensor([ 0.4784])
- Args:
scale (float or Tensor): Scale parameter of distribution (lambda). concentration (float or Tensor): Concentration parameter of distribution (k/shape).
- arg_constraints: Dict[str, constraints.Constraint] = {'concentration': GreaterThan(lower_bound=0.0), 'scale': GreaterThan(lower_bound=0.0)}
- entropy()[source]
Returns entropy of distribution, batched over batch_shape.
- Returns:
Tensor of shape batch_shape.
- expand(batch_shape, _instance=None)[source]
Returns a new distribution instance (or populates an existing instance provided by a derived class) with batch dimensions expanded to batch_shape. This method calls
expandon the distribution’s parameters. As such, this does not allocate new memory for the expanded distribution instance. Additionally, this does not repeat any args checking or parameter broadcasting in __init__.py, when an instance is first created.- Args:
batch_shape (torch.Size): the desired expanded size. _instance: new instance provided by subclasses that
need to override .expand.
- Returns:
New distribution instance with batch dimensions expanded to batch_size.
- property mean
Returns the mean of the distribution.
- property mode
Returns the mode of the distribution.
- support = GreaterThan(lower_bound=0.0)
- property variance
Returns the variance of the distribution.
- class skwdro.distributions.Wishart(df: Tensor | Number, covariance_matrix: Tensor | None = None, precision_matrix: Tensor | None = None, scale_tril: Tensor | None = None, validate_args=None)[source]
Bases:
ExponentialFamilyCreates a Wishart distribution parameterized by a symmetric positive definite matrix
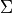 ,
or its Cholesky decomposition
,
or its Cholesky decomposition - Example:
>>> # xdoctest: +SKIP("FIXME: scale_tril must be at least two-dimensional") >>> m = Wishart(torch.Tensor([2]), covariance_matrix=torch.eye(2)) >>> m.sample() # Wishart distributed with mean=`df * I` and >>> # variance(x_ij)=`df` for i != j and variance(x_ij)=`2 * df` for i == j
- Args:
df (float or Tensor): real-valued parameter larger than the (dimension of Square matrix) - 1 covariance_matrix (Tensor): positive-definite covariance matrix precision_matrix (Tensor): positive-definite precision matrix scale_tril (Tensor): lower-triangular factor of covariance, with positive-valued diagonal
- Note:
Only one of
covariance_matrixorprecision_matrixorscale_trilcan be specified. Usingscale_trilwill be more efficient: all computations internally are based onscale_tril. Ifcovariance_matrixorprecision_matrixis passed instead, it is only used to compute the corresponding lower triangular matrices using a Cholesky decomposition. ‘torch.distributions.LKJCholesky’ is a restricted Wishart distribution.[1]
References
[1] Wang, Z., Wu, Y. and Chu, H., 2018. On equivalence of the LKJ distribution and the restricted Wishart distribution. [2] Sawyer, S., 2007. Wishart Distributions and Inverse-Wishart Sampling. [3] Anderson, T. W., 2003. An Introduction to Multivariate Statistical Analysis (3rd ed.). [4] Odell, P. L. & Feiveson, A. H., 1966. A Numerical Procedure to Generate a SampleCovariance Matrix. JASA, 61(313):199-203. [5] Ku, Y.-C. & Bloomfield, P., 2010. Generating Random Wishart Matrices with Fractional Degrees of Freedom in OX.
- arg_constraints = {'covariance_matrix': PositiveDefinite(), 'df': GreaterThan(lower_bound=0), 'precision_matrix': PositiveDefinite(), 'scale_tril': LowerCholesky()}
- property covariance_matrix
- expand(batch_shape, _instance=None)[source]
Returns a new distribution instance (or populates an existing instance provided by a derived class) with batch dimensions expanded to batch_shape. This method calls
expandon the distribution’s parameters. As such, this does not allocate new memory for the expanded distribution instance. Additionally, this does not repeat any args checking or parameter broadcasting in __init__.py, when an instance is first created.- Args:
batch_shape (torch.Size): the desired expanded size. _instance: new instance provided by subclasses that
need to override .expand.
- Returns:
New distribution instance with batch dimensions expanded to batch_size.
- has_rsample = True
- log_prob(value)[source]
Returns the log of the probability density/mass function evaluated at value.
- Args:
value (Tensor):
- property mean
Returns the mean of the distribution.
- property mode
Returns the mode of the distribution.
- property precision_matrix
- rsample(sample_shape: Size | List[int] | Tuple[int, ...] = (), max_try_correction=None) Tensor[source]
Warning
In some cases, sampling algorithm based on Bartlett decomposition may return singular matrix samples. Several tries to correct singular samples are performed by default, but it may end up returning singular matrix samples. Singular samples may return -inf values in .log_prob(). In those cases, the user should validate the samples and either fix the value of df or adjust max_try_correction value for argument in .rsample accordingly.
- property scale_tril
- support = PositiveDefinite()
- property variance
Returns the variance of the distribution.
- skwdro.distributions.kl_divergence(p: Distribution, q: Distribution) Tensor[source]
Compute Kullback-Leibler divergence
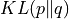 between two distributions.
between two distributions.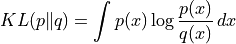
- Args:
p (Distribution): A
Distributionobject. q (Distribution): ADistributionobject.- Returns:
Tensor: A batch of KL divergences of shape batch_shape.
- Raises:
- NotImplementedError: If the distribution types have not been registered via
- KL divergence is currently implemented for the following distribution pairs:
BernoulliandBernoulliBernoulliandPoissonBetaandBetaBetaandContinuousBernoulliBetaandExponentialBetaandGammaBetaandNormalBetaandParetoBetaandUniformBinomialandBinomialCategoricalandCategoricalCauchyandCauchyContinuousBernoulliandContinuousBernoulliContinuousBernoulliandExponentialContinuousBernoulliandNormalContinuousBernoulliandParetoContinuousBernoulliandUniformDirichletandDirichletExponentialandBetaExponentialandContinuousBernoulliExponentialandExponentialExponentialandGammaExponentialandGumbelExponentialandNormalExponentialandParetoExponentialandUniformExponentialFamilyandExponentialFamilyGammaandBetaGammaandContinuousBernoulliGammaandExponentialGammaandGammaGammaandGumbelGammaandNormalGammaandParetoGammaandUniformGeometricandGeometricGumbelandBetaGumbelandContinuousBernoulliGumbelandExponentialGumbelandGammaGumbelandGumbelGumbelandNormalGumbelandParetoGumbelandUniformHalfNormalandHalfNormalIndependentandIndependentLaplaceandBetaLaplaceandContinuousBernoulliLaplaceandExponentialLaplaceandGammaLaplaceandLaplaceLaplaceandNormalLaplaceandParetoLaplaceandUniformLowRankMultivariateNormalandLowRankMultivariateNormalLowRankMultivariateNormalandMultivariateNormalMultivariateNormalandLowRankMultivariateNormalMultivariateNormalandMultivariateNormalNormalandBetaNormalandContinuousBernoulliNormalandExponentialNormalandGammaNormalandGumbelNormalandLaplaceNormalandNormalNormalandParetoNormalandUniformOneHotCategoricalandOneHotCategoricalParetoandBetaParetoandContinuousBernoulliParetoandExponentialParetoandGammaParetoandNormalParetoandParetoParetoandUniformPoissonandBernoulliPoissonandBinomialPoissonandPoissonTransformedDistributionandTransformedDistributionUniformandBetaUniformandContinuousBernoulliUniformandExponentialUniformandGammaUniformandGumbelUniformandNormalUniformandParetoUniformandUniform
- skwdro.distributions.register_kl(type_p, type_q)[source]
Decorator to register a pairwise function with
kl_divergence(). Usage:@register_kl(Normal, Normal) def kl_normal_normal(p, q): # insert implementation here
Lookup returns the most specific (type,type) match ordered by subclass. If the match is ambiguous, a RuntimeWarning is raised. For example to resolve the ambiguous situation:
@register_kl(BaseP, DerivedQ) def kl_version1(p, q): ... @register_kl(DerivedP, BaseQ) def kl_version2(p, q): ...
you should register a third most-specific implementation, e.g.:
register_kl(DerivedP, DerivedQ)(kl_version1) # Break the tie.
- Args:
type_p (type): A subclass of
Distribution. type_q (type): A subclass ofDistribution.