skwdro.linear_models package
Module contents
- class skwdro.linear_models.LinearRegression(rho=0.01, l2_reg=0.0, fit_intercept=True, cost='t-NLC-2-2', solver='entropic_torch', solver_reg=None, sampler_reg=None, n_zeta_samples: int = 10, random_state: int = 0, opt_cond: ~skwdro.solvers.optim_cond.OptCondTorch | None = <skwdro.solvers.optim_cond.OptCondTorch object>)[source]
Bases:
BaseEstimator,RegressorMixinA Wasserstein Distributionally Robust linear regression.
The cost function is
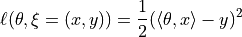
The WDRO problem solved at fitting is
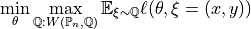
- Parameters:
- rhofloat, default=1e-2
Robustness radius
- l2_regfloat, default=0.
l2 regularization
- fit_interceptboolean, default=True
Determines if an intercept is fit or not
- cost: str, default=”t-NLC-2-2”
Tiret-separated code to define the transport cost: “<engine>-<cost id>-<k-norm type>-<power>” for
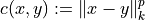
- solver: str, default=’entropic’
Solver to be used: ‘entropic’, ‘entropic_torch’ (_pre or _post) or ‘dedicated’
- solver_reg: float, default=1.0
regularization value for the entropic solver
- n_zeta_samples: int, default=10
number of adversarial samples to draw
- opt_cond: Optional[OptCondTorch]
optimality condition, see
OptCondTorch
- Attributes:
- coef_array, shape (n_features,)
parameter vector (
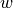 in the cost function formula)
in the cost function formula)- intercept_float
constant term in decision function.
Examples
>>> import numpy as np >>> from skwdro.linear_models import LinearRegression as RobustLinearRegression >>> from sklearn.model_selection import train_test_split >>> d = 10; m = 100 >>> x0 = np.random.randn(d) >>> X = np.random.randn(m,d) >>> y = X.dot(x0) + np.random.randn(m) >>> X_train, X_test, y_train, y_test = train_test_split(X,y) >>> rob_lin = RobustLinearRegression(rho=0.1,solver="entropic",fit_intercept=True) >>> rob_lin.fit(X_train, y_train) LinearRegression(rho=0.1) >>> y_pred_rob = rob_lin.predict(X_test)
- fit(X, y)[source]
Fits the WDRO classifier.
- Parameters:
- Xarray-like, shape (n_samples, n_features)
The training input samples.
- yarray-like, shape (n_samples,)
The target values. An array of int. Only -1 or +1 are currently supported
- Returns:
- selfobject
Returns self.
- predict(X)[source]
Robust prediction.
- Parameters:
- Xarray-like, shape (n_samples, n_features)
The input samples.
- Returns:
- yndarray, shape (n_samples,)
The prediction
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') LinearRegression
Request metadata passed to the
scoremethod.Note that this method is only relevant if
enable_metadata_routing=True(seesklearn.set_config()). Please see User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed toscoreif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it toscore.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.Added in version 1.3.
Note
This method is only relevant if this estimator is used as a sub-estimator of a meta-estimator, e.g. used inside a
Pipeline. Otherwise it has no effect.- Parameters:
- sample_weightstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
sample_weightparameter inscore.
- Returns:
- selfobject
The updated object.
- class skwdro.linear_models.LogisticRegression(rho: float = 0.01, l2_reg: float = 0.0, fit_intercept: bool = True, cost: str = 't-NLC-2-2', solver='entropic_torch', solver_reg: float | None = None, sampler_reg: float | None = None, n_zeta_samples: int = 10, random_state: int = 0, opt_cond: ~skwdro.solvers.optim_cond.OptCondTorch | None = <skwdro.solvers.optim_cond.OptCondTorch object>)[source]
Bases:
BaseEstimator,ClassifierMixinA Wasserstein Distributionally Robust logistic regression classifier.
The cost function is XXX
Uncertainty is XXX
- Parameters:
- rho: float, default=1e-2
Robustness radius
- l2_reg: float, default=None
l2 regularization
- fit_intercept: boolean, default=True
Determines if an intercept is fit or not
- cost: str, default=”n-NC-1-2”
Tiret-separated code to define the transport cost: “<engine>-<cost id>-<k-norm type>-<power>” for
- solver: str, default=’entropic_torch’
Solver to be used: ‘entropic’, ‘entropic_torch’ (_pre or _post) or ‘dedicated’
- solver_reg: float, default=1e-2
regularization value for the entropic solver
- n_zeta_samples: int, default=10
number of adversarial samples to draw
- opt_cond: Optional[OptCondTorch]
optimality condition, see
OptCondTorch
- Attributes:
- coef_array, shape (n_features,)
parameter vector (
in the cost function formula)- intercept_float
constant term in decision function.
Examples
>>> import numpy as np >>> from skwdro.linear_models import LogisticRegression >>> from sklearn.datasets import make_blobs >>> from sklearn.model_selection import train_test_split >>> X, y = make_blobs(n_samples=100, centers=2, n_features=2, random_state=0) >>> y = np.sign(y-0.5) >>> X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42) >>> estimator = LogisticRegression() >>> estimator.fit(X_train,y_train) LogisticRegression() >>> estimator.predict(X_test) array([-1., -1., -1., 1., -1., 1., 1., -1., -1., 1., 1., 1., -1., 1., 1., 1., 1., 1., -1., -1., -1., 1., 1., -1., -1., 1., -1., 1., 1., 1., 1., 1., -1.]) >>> estimator.score(X_test,y_test) 0.9393939393939394
- fit(X, y)[source]
Fits the WDRO classifier.
- Parameters:
- Xarray-like, shape (n_samples, n_features)
The training input samples.
- yarray-like, shape (n_samples,)
The target values. An array of int. Only -1 or +1 are currently supported
- Returns:
- selfLogisticRegression
Returns self.
- predict(X)[source]
Robust prediction.
- Parameters:
- Xarray-like, shape (n_samples, n_features)
The input samples.
- Returns:
- yndarray, shape (n_samples,)
The label for each sample is the label of the closest sample seen during fit.
- predict_proba(X)[source]
Robust prediction probability for classes -1 and +1.
- Parameters:
- Xarray-like, shape (n_samples, n_features)
The input samples.
- Returns:
- pndarray, shape (n_samples,2)
The probability of each class for each of the samples.
- predict_proba_2Class(X)[source]
Robust prediction probability for class +1.
- Parameters:
- Xarray-like, shape (n_samples, n_features)
The input samples.
- Returns:
- pndarray, shape (n_samples,)
The probability of class +1 for each of the samples.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') LogisticRegression
Request metadata passed to the
scoremethod.Note that this method is only relevant if
enable_metadata_routing=True(seesklearn.set_config()). Please see User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed toscoreif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it toscore.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.Added in version 1.3.
Note
This method is only relevant if this estimator is used as a sub-estimator of a meta-estimator, e.g. used inside a
Pipeline. Otherwise it has no effect.- Parameters:
- sample_weightstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
sample_weightparameter inscore.
- Returns:
- selfobject
The updated object.