skwdro.solvers package
Submodules
skwdro.solvers.entropic_dual_torch module
- skwdro.solvers.entropic_dual_torch.extract_data(dist: Distribution)[source]
Get torch tensors out of empirical distribution.
- Parameters:
- dist: Distribution
Empirical distribution of data and optionally labels
- Returns:
- xi: pt.Tensor
data tensor
- xi_labels: Optional[pt.Tensor]
label tensor if the distribution yields them, else
None
- skwdro.solvers.entropic_dual_torch.optim_postsample(optimizer: Optimizer, xi: Tensor, xi_labels: Tensor | None, loss: _DualLoss, opt_cond: OptCondTorch) List[float][source]
Optimize the dual loss by resampling the
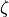 values at each
gradient descent step.
values at each
gradient descent step.- Parameters:
- n_iterint
number of gradient descent iterations to perform
- optimizerpt.optim.Optimizer
loss-dependant optimizer, can be customized if needed
- xipt.Tensor
data tensor
- xi_labelsOptional[pt.Tensor]
target tensor
- loss_DualLoss
dual loss instance
- Returns:
- List[float]
- skwdro.solvers.entropic_dual_torch.optim_presample(optimizer: Optimizer, xi: Tensor, xi_labels: Tensor | None, loss: _DualLoss, opt_cond: OptCondTorch) List[float][source]
Optimize the dual loss by sampling the
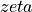 values once at
the begining of the optimization, then performing a deterministic
gradient descent (e.g. BFGS style algorithm).
values once at
the begining of the optimization, then performing a deterministic
gradient descent (e.g. BFGS style algorithm).- Parameters:
- optimizerpt.optim.Optimizer
loss-dependant optimizer, can be customized if needed
- xipt.Tensor
data tensor
- xi_labelsOptional[pt.Tensor]
target tensor
- loss_DualLoss
dual loss instance
- Returns:
- List[float]
- skwdro.solvers.entropic_dual_torch.solve_dual_wdro(loss: _DualLoss, p_hat: Distribution, opt: OptCondTorch)[source]
Solve the dual problem with the loss-dependant grandient descent algorithm.
- Parameters:
- loss: _DualLoss
Dual loss
- p_hat: Distribution
Empirical distribution
- opt: OptCond
Optimality conditions
- Returns:
- theta: np.ndarray
Concatenated array of the parameters of the model, except the intercept if there is one
- intercept: Optional[np.ndarray]
If the model has specificaly an intercept as one of its parameters, it is stacked in this output tensor
- lambd: Union[np.ndarray, float]
Dual variable
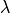 of the problem
of the problem
skwdro.solvers.entropic_dual_torch_epsilon module
- skwdro.solvers.entropic_dual_torch_epsilon.extract_data(dist: Distribution)[source]
Get torch tensors out of empirical distribution.
- Parameters:
- dist: Distribution
Empirical distribution of data and optionally labels
- Returns:
- xi: pt.Tensor
data tensor
- xi_labels: Optional[pt.Tensor]
label tensor if the distribution yields them, else
None
- skwdro.solvers.entropic_dual_torch_epsilon.optim_postsample(optimizer: Optimizer, xi: Tensor, xi_labels: Tensor | None, loss: _DualLoss, opt_cond: OptCondTorch) List[Tensor][source]
Optimize the dual loss by resampling the
values at each gradient descent step.- Parameters:
- n_iterint
number of gradient descent iterations to perform
- optimizerpt.optim.Optimizer
loss-dependant optimizer, can be customized if needed
- xipt.Tensor
data tensor
- xi_labelsOptional[pt.Tensor]
target tensor
- loss_DualLoss
dual loss instance
- Returns:
- List[float]
- skwdro.solvers.entropic_dual_torch_epsilon.optim_presample(optimizer: Optimizer, xi: Tensor, xi_labels: Tensor | None, loss: _DualLoss, opt_cond: OptCondTorch) List[float][source]
Optimize the dual loss by sampling the
values once at the begining of
the optimization, the performing a deterministic gradient descent (e.g. BFGS style algorithm).- Parameters:
- optimizerpt.optim.Optimizer
loss-dependant optimizer, can be customized if needed
- xipt.Tensor
data tensor
- xi_labelsOptional[pt.Tensor]
target tensor
- loss_DualLoss
dual loss instance
- Returns:
- List[float]
- skwdro.solvers.entropic_dual_torch_epsilon.solve_dual_wdro(loss: _DualLoss, p_hat: Distribution, opt: OptCondTorch)[source]
Solve the dual problem with the loss-dependant grandient descent algorithm.
- Parameters:
- loss: _DualLoss
Dual loss
- p_hat: Distribution
Empirical distribution
- opt: OptCond
Optimality conditions
- Returns:
- theta: np.ndarray
Concatenated array of the parameters of the model, except the intercept if there is one
- intercept: Optional[np.ndarray]
If the model has specificaly an intercept as one of its parameters, it is stacked in this output tensor
- lambd: Union[np.ndarray, float]
Dual variable
of the problem
skwdro.solvers.hybrid_opt module
skwdro.solvers.optim_cond module
- class skwdro.solvers.optim_cond.OptCondTorch(order: int | str, tol_theta: float = 1e-08, tol_lambda: float = 1e-08, *, monitoring: str = 'theta', mode: str = 'rel', metric: str = 'grad', verbose: bool = False)[source]
Bases:
objectCallable object representing some optimality conditions
May track two different expression of the error: * the relative error:
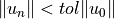 * the absolute error:
* the absolute error: 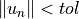
Those equations are evaluated for three possible metrics
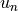 :
:the progress in the gradient of the dual loss with respect to the
parameter of interest
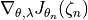 * the progress of the parameters themselves
* the progress of the parameters themselves
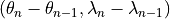
To evaluate the above metrics, one may chose to monitor the convergence in:
only
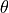
only
both
or either
- Parameters:
- order: int|str
norm type to use
- tol_theta: float
if positive, the tolerance (relative or absolute) to allow for the parameters, if <=0 ignores it
- tol_lambda: float
if positive, the tolerance (relative or absolute) to allow for the dual parameter, if <=0 ignores it
- monitoring: str
see the global variables
L_OR_T(for either convergence to allow stop),L_AND_T(for joint convergence to allow stop),JUST_L(for only),
JUST_T(for only) to have the allowed
options- mode: str
either
"rel"for relative progress or"abs"for absolute progress. Not checked if the metric is the gradient value- metric:
either
"grad"for gradient improvement/change over time, or"param"for parameter-space improvement/change over time
- check_all_params(lam: Callable[[], Tensor], lamgrad: Callable[[], Tensor], flattheta: Callable[[], Tensor], flatgrad: Callable[[], Tensor]) Tuple[bool, float][source]
Checks the dual and primal parameters for convergence by using functional monads on the tensors, see
check_t()andcheck_l().- Returns:
- cond: bool
green light to stop algorithm
- check_iter(it_number: int) bool[source]
Checks if the maximum number of iterations has been crossed
- Returns:
- cond: bool
green light to stop algorithm
- check_l(lam: Callable[[], Tensor], lam_grad: Callable[[], Tensor]) Tuple[bool, float][source]
Check the convergence of the theta parameter, either in gradient or in parameter value. The parameters are ``LazyTensor``s which means that they must be called as functions to be evaluated
- Returns:
- cond: bool
green light to stop algorithm
- check_metric(new_obs: Tensor, memory: Tensor, tol: float) Tuple[bool, float][source]
Helper function to get the tolerance check in both the relative and absolute error cases.
- Parameters:
- new_obs: pt.Tensor
current step metric
- memory: pt.Tensor
same metric at last step – initialized at None, so a check must be performed before call to this function
- tol: float
the positive tolerance rate allowed (same for absolute and relative tolerance)
- Returns:
- cond: bool
green light to stop algorithm
- check_t(flat_theta: Callable[[], Tensor], flat_theta_grad: Callable[[], Tensor]) Tuple[bool, float][source]
Check the convergence of the theta parameter, either in gradient or in parameter value. The parameters are ``LazyTensor``s which means that they must be called as functions to be evaluated.
- Returns:
- cond: bool
green light to stop algorithm
- skwdro.solvers.optim_cond.combine_intersect(a: Tuple[bool, float], b: Tuple[bool, float]) Tuple[bool, float][source]
skwdro.solvers.oracle_torch module
- class skwdro.solvers.oracle_torch.CompositeOptimizer(params, lbd, n_iter, optimizer)[source]
Bases:
Optimizer- load_state_dict(state_dict)[source]
Load the optimizer state.
- Args:
- state_dict (dict): optimizer state. Should be an object returned
from a call to
state_dict().
- state_dict()[source]
Return the state of the optimizer as a
dict.It contains two entries:
state: a Dict holding current optimization state. Its contentdiffers between optimizer classes, but some common characteristics hold. For example, state is saved per parameter, and the parameter itself is NOT saved.
stateis a Dictionary mapping parameter ids to a Dict with state corresponding to each parameter.
param_groups: a List containing all parameter groups where eachparameter group is a Dict. Each parameter group contains metadata specific to the optimizer, such as learning rate and weight decay, as well as a List of parameter IDs of the parameters in the group.
NOTE: The parameter IDs may look like indices but they are just IDs associating state with param_group. When loading from a state_dict, the optimizer will zip the param_group
params(int IDs) and the optimizerparam_groups(actualnn.Parameters) in order to match state WITHOUT additional verification.A returned state dict might look something like:
{ 'state': { 0: {'momentum_buffer': tensor(...), ...}, 1: {'momentum_buffer': tensor(...), ...}, 2: {'momentum_buffer': tensor(...), ...}, 3: {'momentum_buffer': tensor(...), ...} }, 'param_groups': [ { 'lr': 0.01, 'weight_decay': 0, ... 'params': [0] }, { 'lr': 0.001, 'weight_decay': 0.5, ... 'params': [1, 2, 3] } ] }
- step(closure: None = None) None[source]
- step(closure: Callable) float
Perform a single optimization step to update parameter.
- Args:
- closure (Callable): A closure that reevaluates the model and
returns the loss. Optional for most optimizers.
Note
Unless otherwise specified, this function should not modify the
.gradfield of the parameters.
- zero_grad(*args, **kwargs)[source]
Reset the gradients of all optimized
torch.Tensors.- Args:
- set_to_none (bool): instead of setting to zero, set the grads to None.
This will in general have lower memory footprint, and can modestly improve performance. However, it changes certain behaviors. For example: 1. When the user tries to access a gradient and perform manual ops on it, a None attribute or a Tensor full of 0s will behave differently. 2. If the user requests
zero_grad(set_to_none=True)followed by a backward pass,.grads are guaranteed to be None for params that did not receive a gradient. 3.torch.optimoptimizers have a different behavior if the gradient is 0 or None (in one case it does the step with a gradient of 0 and in the other it skips the step altogether).
- skwdro.solvers.oracle_torch.DualLoss
alias of
DualPostSampledLoss
- class skwdro.solvers.oracle_torch.DualPostSampledLoss(loss: Loss, cost: TorchCost, n_samples: int, epsilon_0: Tensor, rho_0: Tensor, n_iter: int | Tuple[int, int] = 10000, gradient_hypertuning: bool = False, *, imp_samp: bool = True, adapt: str | None = 'prodigy')[source]
Bases:
_DualLossDual loss implementing a sampling of the
vectors at
each forward pass.- Parameters:
- lossLoss
the loss of interest
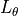
- costCost
ground-distance function
- n_samplesint
number of
samples to draw at each forward pass
- forward(xi: Tensor, xi_labels: Tensor | None = None, zeta: None = None, zeta_labels: None = None, reset_sampler: bool = False) Tensor[source]
- forward(xi: Tensor, xi_labels: Tensor | None, zeta: Tensor, zeta_labels: Tensor | None = None, reset_sampler: bool = False) Tensor
Forward pass for the dual loss, with the sampling of the adversarial samples
- Parameters:
- xipt.Tensor
data batch
- xi_labelsOptional[pt.Tensor]
labels batch
- reset_samplerbool
defaults to
False, if set resets the batch saved in the sampler
- Returns:
- dlpt.Tensor
- property presample
TrueforDualPreSampledLoss,FalseforDualPostSampledLoss.- Returns:
- bool
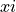 data.
data.- class skwdro.solvers.oracle_torch.DualPreSampledLoss(loss: Loss, cost: TorchCost, n_samples: int, epsilon_0: Tensor, rho_0: Tensor, n_iter: int | Tuple[int, int] = 50, gradient_hypertuning: bool = False, *, imp_samp: bool = True, adapt: str | None = 'prodigy')[source]
Bases:
_DualLossDual loss implementing a forward pass without resampling the
vectors.- Parameters:
- lossLoss
the loss of interest
- costCost
ground-distance function
- n_samplesint
number of
samples to draw before the gradient
descent begins (can be changed if needed between inferences).
- forward(xi: Tensor, xi_labels: Tensor | None = None, zeta: None = None, zeta_labels: None = None, reset_sampler: bool = False) Tensor[source]
- forward(xi: Tensor, xi_labels: Tensor | None, zeta: Tensor, zeta_labels: Tensor | None = None, reset_sampler: bool = False)
Forward pass for the dual loss, wrt the already sampled
values- Parameters:
- xipt.Tensor
data batch
- xi_labelsOptional[pt.Tensor]
labels batch
- zetaOptional[pt.Tensor]
data batch
- zeta_labelsOptional[pt.Tensor]
labels batch
- Returns:
- dlpt.Tensor
- property presample
TrueforDualPreSampledLoss,FalseforDualPostSampledLoss.- Returns:
- bool
skwdro.solvers.result module
skwdro.solvers.specific_solvers module
- skwdro.solvers.specific_solvers.WDROLinRegSpecificSolver(rho: float = 1.0, X: ndarray = array(None, dtype=object), y: ndarray = array(None, dtype=object), fit_intercept: bool = False)[source]
- skwdro.solvers.specific_solvers.WDROLogisticSpecificSolver(rho=1.0, kappa=1000, X=None, y=None, fit_intercept=False)[source]
skwdro.solvers.utils module
- exception skwdro.solvers.utils.NoneGradError[source]
Bases:
ValueError
- skwdro.solvers.utils.diff_opt_tensor(tensor: Tensor | None, us_dim: int | None = 0) Tensor | None[source]
- skwdro.solvers.utils.interpret_steps_struct(steps_spec: int | Tuple[int, int], default_split: float = 0.3) Tuple[int, int][source]
Module contents
- skwdro.solvers.BaseDualLoss
alias of
_DualLoss
- skwdro.solvers.DualLoss
alias of
DualPostSampledLoss
- class skwdro.solvers.DualPostSampledLoss(loss: Loss, cost: TorchCost, n_samples: int, epsilon_0: Tensor, rho_0: Tensor, n_iter: int | Tuple[int, int] = 10000, gradient_hypertuning: bool = False, *, imp_samp: bool = True, adapt: str | None = 'prodigy')[source]
Bases:
_DualLossDual loss implementing a sampling of the
vectors at
each forward pass.- Parameters:
- lossLoss
the loss of interest
- costCost
ground-distance function
- n_samplesint
number of
samples to draw at each forward pass
- forward(xi: Tensor, xi_labels: Tensor | None = None, zeta: None = None, zeta_labels: None = None, reset_sampler: bool = False) Tensor[source]
- forward(xi: Tensor, xi_labels: Tensor | None, zeta: Tensor, zeta_labels: Tensor | None = None, reset_sampler: bool = False) Tensor
Forward pass for the dual loss, with the sampling of the adversarial samples
- Parameters:
- xipt.Tensor
data batch
- xi_labelsOptional[pt.Tensor]
labels batch
- reset_samplerbool
defaults to
False, if set resets the batch saved in the sampler
- Returns:
- dlpt.Tensor
- property presample
TrueforDualPreSampledLoss,FalseforDualPostSampledLoss.- Returns:
- bool
- class skwdro.solvers.DualPreSampledLoss(loss: Loss, cost: TorchCost, n_samples: int, epsilon_0: Tensor, rho_0: Tensor, n_iter: int | Tuple[int, int] = 50, gradient_hypertuning: bool = False, *, imp_samp: bool = True, adapt: str | None = 'prodigy')[source]
Bases:
_DualLossDual loss implementing a forward pass without resampling the
vectors.- Parameters:
- lossLoss
the loss of interest
- costCost
ground-distance function
- n_samplesint
number of
samples to draw before the gradient
descent begins (can be changed if needed between inferences).
- forward(xi: Tensor, xi_labels: Tensor | None = None, zeta: None = None, zeta_labels: None = None, reset_sampler: bool = False) Tensor[source]
- forward(xi: Tensor, xi_labels: Tensor | None, zeta: Tensor, zeta_labels: Tensor | None = None, reset_sampler: bool = False)
Forward pass for the dual loss, wrt the already sampled
values- Parameters:
- xipt.Tensor
data batch
- xi_labelsOptional[pt.Tensor]
labels batch
- zetaOptional[pt.Tensor]
data batch
- zeta_labelsOptional[pt.Tensor]
labels batch
- Returns:
- dlpt.Tensor
- property presample
TrueforDualPreSampledLoss,FalseforDualPostSampledLoss.- Returns:
- bool
- exception skwdro.solvers.NoneGradError[source]
Bases:
ValueError
- skwdro.solvers.diff_opt_tensor(tensor: Tensor | None, us_dim: int | None = 0) Tensor | None[source]