Tuning of the Wasserstein radius hyperparameter
The following hyperparameter tuning methods are implemented in skwdro.
Tuning using scikit-learn’s GridSearchCV
This tuning method creates an instance of scikit-learn’s GridSearchCV class to choose 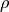 .
.
This method performs an exhaustive search for the best hyperparameter with respect to
all problem parameters in a discrete interval. It is based on the
score method mentioned earlier, which is present for every estimator. For problems inheriting
of ClassifierMixin and RegressorMixin, these methods are inherited and are based on
model accuracy measures specific to these classes. For other problems, you need to
write this method. It simply returns the optimal value of the loss function
multiplied by -1, since by default, scikit-learn’s scoring methods aim to
maximize the score function. Thus, the value of that maximizes the score function
via cross-validation is chosen and returned by GridSearchCV. We use
k-block cross-validation, where k = 5 is a commonly used value.
Another class from scikit-learn that can be used for the tuning, by replacing in the tuning file the name of the class when creating the instance, is HalvingGridSearchCV. This method selects the right hyperparameters via a tournament selection, growing the sample size bit by bit and studying the results at each iteration. This method seems faster than GridSearchCV, however, it is still experimental within scikit_learn, and therefore potentially unstable for the skwdro structure in the future.
Tuning using statistical methods
This tuning method is based on an algorithm from Blanchet’s 2021 paper “Statistical Analysis of Wasser-
stein Distributionally Robust Estimators” (see https://arxiv.org/abs/2108.02120 for more details). It is based on rewriting the general stochastic
optimization problem as a statistical hypothesis test, and deducing an estimation for a good value of that guarantees the presence
of a minimizer in the Wasserstein ball with high probability.
This method doesn’t work with the NewsVendor problem as it exploits the second derivative with respect to the decision 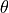 and
the sample parameter
and
the sample parameter 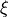 , and this derivative is equal to zero. This fact breaks the structure of the algorithm, because the
value of
, and this derivative is equal to zero. This fact breaks the structure of the algorithm, because the
value of 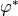 as described in the above paper will be unbounded.
as described in the above paper will be unbounded.