skwdro package
Subpackages
- skwdro.distributions package
- Submodules
- skwdro.distributions.dirac_distribution module
- Module contents
AbsTransformAffineTransformBernoulliBetaBinomialCatTransformCategoricalCategorical.arg_constraintsCategorical.entropy()Categorical.enumerate_support()Categorical.expand()Categorical.has_enumerate_supportCategorical.log_prob()Categorical.logitsCategorical.meanCategorical.modeCategorical.param_shapeCategorical.probsCategorical.sample()Categorical.supportCategorical.variance
CauchyChi2ComposeTransformContinuousBernoulliContinuousBernoulli.arg_constraintsContinuousBernoulli.cdf()ContinuousBernoulli.entropy()ContinuousBernoulli.expand()ContinuousBernoulli.has_rsampleContinuousBernoulli.icdf()ContinuousBernoulli.log_prob()ContinuousBernoulli.logitsContinuousBernoulli.meanContinuousBernoulli.param_shapeContinuousBernoulli.probsContinuousBernoulli.rsample()ContinuousBernoulli.sample()ContinuousBernoulli.stddevContinuousBernoulli.supportContinuousBernoulli.variance
CorrCholeskyTransformCumulativeDistributionTransformDiracDirichletDistributionDistribution.arg_constraintsDistribution.batch_shapeDistribution.cdf()Distribution.entropy()Distribution.enumerate_support()Distribution.event_shapeDistribution.expand()Distribution.has_enumerate_supportDistribution.has_rsampleDistribution.icdf()Distribution.log_prob()Distribution.meanDistribution.modeDistribution.perplexity()Distribution.rsample()Distribution.sample()Distribution.sample_n()Distribution.set_default_validate_args()Distribution.stddevDistribution.supportDistribution.variance
ExpTransformExponentialExponentialFamilyFisherSnedecorGammaGeometricGumbelHalfCauchyHalfNormalIndependentIndependent.arg_constraintsIndependent.entropy()Independent.enumerate_support()Independent.expand()Independent.has_enumerate_supportIndependent.has_rsampleIndependent.log_prob()Independent.meanIndependent.modeIndependent.rsample()Independent.sample()Independent.supportIndependent.variance
IndependentTransformInverseGammaKumaraswamyLKJCholeskyLaplaceLogNormalLogisticNormalLowRankMultivariateNormalLowRankMultivariateNormal.arg_constraintsLowRankMultivariateNormal.covariance_matrixLowRankMultivariateNormal.entropy()LowRankMultivariateNormal.expand()LowRankMultivariateNormal.has_rsampleLowRankMultivariateNormal.log_prob()LowRankMultivariateNormal.meanLowRankMultivariateNormal.modeLowRankMultivariateNormal.precision_matrixLowRankMultivariateNormal.rsample()LowRankMultivariateNormal.scale_trilLowRankMultivariateNormal.supportLowRankMultivariateNormal.variance
LowerCholeskyTransformMixtureSameFamilyMixtureSameFamily.arg_constraintsMixtureSameFamily.cdf()MixtureSameFamily.component_distributionMixtureSameFamily.expand()MixtureSameFamily.has_rsampleMixtureSameFamily.log_prob()MixtureSameFamily.meanMixtureSameFamily.mixture_distributionMixtureSameFamily.sample()MixtureSameFamily.supportMixtureSameFamily.variance
MultinomialMultivariateNormalMultivariateNormal.arg_constraintsMultivariateNormal.covariance_matrixMultivariateNormal.entropy()MultivariateNormal.expand()MultivariateNormal.has_rsampleMultivariateNormal.log_prob()MultivariateNormal.meanMultivariateNormal.modeMultivariateNormal.precision_matrixMultivariateNormal.rsample()MultivariateNormal.scale_trilMultivariateNormal.supportMultivariateNormal.variance
NegativeBinomialNormalOneHotCategoricalOneHotCategorical.arg_constraintsOneHotCategorical.entropy()OneHotCategorical.enumerate_support()OneHotCategorical.expand()OneHotCategorical.has_enumerate_supportOneHotCategorical.log_prob()OneHotCategorical.logitsOneHotCategorical.meanOneHotCategorical.modeOneHotCategorical.param_shapeOneHotCategorical.probsOneHotCategorical.sample()OneHotCategorical.supportOneHotCategorical.variance
OneHotCategoricalStraightThroughParetoPoissonPositiveDefiniteTransformPowerTransformRelaxedBernoulliRelaxedOneHotCategoricalReshapeTransformSigmoidTransformSoftmaxTransformSoftplusTransformStackTransformStickBreakingTransformStudentTTanhTransformTransformTransformedDistributionTransformedDistribution.arg_constraintsTransformedDistribution.cdf()TransformedDistribution.expand()TransformedDistribution.has_rsampleTransformedDistribution.icdf()TransformedDistribution.log_prob()TransformedDistribution.rsample()TransformedDistribution.sample()TransformedDistribution.support
UniformVonMisesWeibullWishartkl_divergence()register_kl()
- skwdro.linear_models package
- skwdro.neural_network package
- skwdro.operations_research package
- skwdro.solvers package
- Submodules
- skwdro.solvers.entropic_dual_torch module
- skwdro.solvers.entropic_dual_torch_epsilon module
- skwdro.solvers.hybrid_opt module
- skwdro.solvers.optim_cond module
- skwdro.solvers.oracle_torch module
- skwdro.solvers.result module
- skwdro.solvers.specific_solvers module
- skwdro.solvers.utils module
- Module contents
- skwdro.tests package
Submodules
skwdro.torch module
skwdro.wrap_problem module
- skwdro.wrap_problem.dualize_primal_loss(loss_: Module, transform_: Module | None, rho: Tensor, xi_batchinit: Tensor, xi_labels_batchinit: Tensor | None, post_sample: bool = True, cost_spec: str | None = None, n_samples: int = 10, seed: int = 42, *, epsilon: float | None = None, sigma: float | None = None, l2reg: float | None = None, adapt: str | None = 'prodigy', imp_samp: bool = True) _DualLoss[source]
Provide the wrapped version of the primal loss.
- Parameters:
- loss_: nn.Module
the primal loss
- transform_: nn.Module
the transformation to apply to the data before feeding it to the loss
- rho: Tensor, shape (n_samples,)
Wasserstein radius
- xi_batchinit: Tensor, shape (n_samples, n_features)
Data points to initialize the samplers and
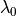
- xi_labels_batchinit: Optional[Tensor], shape (n_samples, n_features)
Labels to initialize the samplers and
- post_sample: bool
whether to use a post-sampled dual loss
- cost_spec: str|None
the cost specification in the format
(k, p)for a sample k-norm and p-power.Noneto use the default(2, 2).- n_samples: int
number of
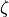 samples to draw before the gradient
descent begins (can be changed if needed between inferences)
samples to draw before the gradient
descent begins (can be changed if needed between inferences)- seed: int
the seed for the samplers
- epsilon: float|None
Epsilon if hard coded,
Noneto let the algo find it.- sigma: float|None
Sigma if hard coded,
Noneto let the algo find it.- l2reg: float|None
L2 regularization if needed
- adapt: str|None
the adaptative step to use between “prodigy” and “mechanic”.
- imp_samp: bool
whether to use importance sampling (will work only for
(2, 2)costs).
- skwdro.wrap_problem.expert_hyperparams(rho: Tensor, p: float, epsilon: float | None, epsilon_sigma_factor: float, sigma: float | None, sigma_factor: float) Tuple[Tensor, Tensor][source]
Tuning of the hyperparameters for the dual loss.
- Parameters:
- rho: Tensor, shape (n_samples,)
Wasserstein radius
- p: float
power of norm
- epsilon: float
Epsilon if hard coded,
Noneto let the algo find it.- epsilon_sigma_factor: float
Estimated ratio

- sigma: float
Sigma if hard coded,
Noneto let the algo find it.- sigma_factor: float
Estimated ratio