Note
Go to the end to download the full example code.
Robustify a neural-net on spatial perturbations of the “moons” non-convex dataset#
This example illustrates the use of the skwdro.torch.robustify wrapper to solve non-convex datasets that are shifted at test time with a PyTorch neural network.
It showcases the ease of use of the interface, and the way you can wrap the estimator easily in a scikit-learn pipeline.
import numpy as np
from sklearn.datasets import make_moons
from typing import Optional
import numpy as np
import torch as pt
import torch.nn as nn
from sklearn.base import BaseEstimator, ClassifierMixin
from sklearn.utils.validation import check_X_y, check_array, check_is_fitted
from sklearn.utils.multiclass import unique_labels
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn.exceptions import DataConversionWarning
from scipy.special import expit
from skwdro.base.problems import EmpiricalDistributionWithLabels
from skwdro.base.losses_torch.logistic import BiDiffSoftMarginLoss
from skwdro.solvers.optim_cond import OptCondTorch
from skwdro.base.cost_decoder import cost_from_str
import skwdro.solvers.entropic_dual_torch as entTorch
from skwdro.wrap_problem import dualize_primal_loss
from utils.classifier_comparison import plot_classifier_comparison
Bellow is a simple neural network architecture to classify (2-classes) the moons
dataset. It’s almost a 1-to-1 copy of the skwdro.linear_model.LogisticRegression.
By default, it contains only 1 hidden layer of 32 neurons.
So its shape/architecture is \(\mathbb{R}^2\to\mathbb{R}^32\to\mathbb{R}\)
Note
Try it at home! Change the architecture and try to see how it changes the results and the stability of the algorithm.
class NeuralNetClassifier(BaseEstimator, ClassifierMixin):
r""" A Wasserstein Distributionally Robust neural classifier.
Parameters
----------
rho: float, default=1e-2
Robustness radius
l2_reg: float, default=None
l2 regularization
fit_intercept: boolean, default=True
Determines if an intercept is fit or not
cost: str, default="n-NC-1-2"
Tiret-separated code to define the transport cost:
"<engine>-<cost id>-<k-norm type>-<power>"
for :math:`c(x, y):=\|x-y\|_k^p`
solver: str, default='entropic_torch'
Solver to be used: 'entropic', 'entropic_torch'
(_pre or _post) or 'dedicated'
solver_reg: float | None, default=None
regularization value for the entropic solver, has
a default heuristic
sampler_reg: float | None, default=None
standard deviation of the regularization distribution :math:`\pi_0`, has
a default heuristic
learning_rate: float | None, default=None
if not set, use a default value depending on the problem, else
specifies the stepsize of the gradient descent algorithm
n_zeta_samples: int, default=10
number of adversarial samples to draw
opt_cond: Optional[OptCondTorch]
optimality condition, see :py:class:`OptCondTorch`
Attributes
----------
coef_ : array, shape (n_features,)
parameter vector (:math:`w` in the cost function formula)
intercept_ : float
constant term in decision function.
"""
DEFAULT_OCOND = OptCondTorch(2, 1e-4, 0.)
def __init__(self,
rho: float = 1e-2,
n_hidden_layers: int = 1,
n_hidden_neurons: int = 32,
l2_reg: float = 0.,
fit_intercept: bool = True,
cost: str = "t-NLC-2-2",
solver="entropic_torch",
solver_reg: Optional[float] = None,
sampler_reg: Optional[float] = None,
learning_rate: Optional[float] = None,
n_zeta_samples: int = 10,
random_state: int = 0,
opt_cond: Optional[OptCondTorch] = DEFAULT_OCOND
):
if rho < 0:
raise ValueError(
' '.join([
"The uncertainty radius rho should be",
"non-negative, received",
f"{rho}"
])
)
self.rho = rho
assert n_hidden_layers > 0
self.n_hidden_layers = n_hidden_layers
self.n_hidden_neurons = n_hidden_neurons
self.l2_reg = l2_reg
self.cost = cost
self.fit_intercept = fit_intercept
self.solver = solver
self.solver_reg = solver_reg
self.sampler_reg = sampler_reg # sigma
self.learning_rate = learning_rate
self.opt_cond = opt_cond
self.n_zeta_samples = n_zeta_samples
self.random_state = random_state
def fit(self, X, y):
"""Fits the WDRO classifier.
Parameters
----------
X : array-like, shape (n_samples, n_features)
The training input samples.
y : array-like, shape (n_samples,)
The target values. An array of int. Only -1 or +1 are currently
supported
Returns
-------
self : LogisticRegression
Returns self.
"""
# Check that X and y have correct shape
X, y = check_X_y(X, y)
X = np.array(X)
y = np.array(y)
# Type checking for rho
if self.rho is not float:
try:
self.rho = float(self.rho)
except BaseException:
raise TypeError(
' '.join([
"The uncertainty radius rho should be"
f"numeric, received {type(self.rho)}"
])
)
if len(y.shape) != 1:
y = y.ravel()
raise DataConversionWarning(
f"Given y is {y.shape}, while expected shape is (n_sample,)")
# Store the classes seen during fit
self.classes_ = unique_labels(y)
# Encode the labels
if len(self.classes_) == 2:
# Binary classification
self.le_ = LabelEncoder()
y = self.le_.fit_transform(y)
if y is None:
raise ValueError(
"Problem with labels, none out of label encoder"
)
else:
y = np.array(y, dtype=X.dtype)
y[y == 0.] = -1.
elif len(self.classes_) > 2:
# Multiclass classification
self.le_ = OneHotEncoder(sparse_output=False)
y = self.le_.fit_transform(y[:, None])
if y is None:
raise ValueError(
"Problem with labels, none out of label encoder"
)
else:
y = np.array(y, dtype=X.dtype)
else:
raise ValueError(
' '.join([
f"Found {len(self.classes_)} classes,",
"while (at least) 2 are expected."
])
)
# Check type
if not np.issubdtype(X.dtype, np.number):
raise ValueError(f"Input X has dtype {X.dtype}")
# Store data
self.X_ = X
self.y_ = y
# Setup problem parameters ################
m, d = np.shape(X)
self.n_features_in_ = d
samples_y = y[:, None] if len(self.classes_) == 2 else y
emp = EmpiricalDistributionWithLabels(
m=m,
samples_x=X,
samples_y=samples_y
)
# Define cleanly the hyperparameters of the problem.
self.cost_ = cost_from_str(self.cost)
# #########################################
if self.solver == "entropic":
raise DeprecationWarning(
"The entropic (numpy) solver is now deprecated"
)
elif "torch" in self.solver:
_post_sample = (
self.solver in ("entropic_torch", "entropic_torch_post")
)
assert len(self.classes_) == 2
module_out = 1
loss = BiDiffSoftMarginLoss(reduction='none')
self.wdro_loss_ = dualize_primal_loss(
loss,
nn.Sequential(
nn.Linear(
self.n_features_in_,
self.n_hidden_neurons,
bias=self.fit_intercept
),
nn.ReLU(),
*[
(
nn.Linear(
self.n_hidden_neurons,
self.n_hidden_neurons,
bias=self.fit_intercept
) if i % 2 == 0 else nn.ReLU()
)
for i in range(2 * self.n_hidden_layers)
],
nn.Linear(
self.n_hidden_neurons,
module_out,
bias=self.fit_intercept
)
),
pt.tensor(self.rho),
pt.Tensor(emp.samples_x),
pt.Tensor(emp.samples_y),
_post_sample,
self.cost,
self.n_zeta_samples,
self.random_state,
learning_rate=self.learning_rate,
sigma=self.sampler_reg,
epsilon=self.solver_reg,
imp_samp=_post_sample, # hard set
adapt="prodigy" if self.learning_rate is None else None,
l2reg=self.l2_reg
)
self.wdro_loss_.n_iter = 50, 200
# The problem is solved with the new "dual loss"
self.coef_, _, self.dual_var_, self.robust_loss_ = entTorch.solve_dual_wdro(
self.wdro_loss_,
emp,
self.opt_cond # type: ignore
)
self.coef_ = (
self
.wdro_loss_
.primal_loss
)
# Unknown solver
else:
raise NotImplementedError()
self.is_fitted_ = True
# Return the classifier
return self
def predict_proba_2Class(self, X):
""" Robust prediction probability for class +1.
Parameters
----------
X : array-like, shape (n_samples, n_features)
The input samples.
Returns
-------
p : ndarray, shape (n_samples,)
The probability of class +1 for each of the samples.
"""
# Check is fit had been called
check_is_fitted(self, ['X_', 'y_'])
# Input validation
X = check_array(X)
p = expit(
self.wdro_loss_.primal_loss.transform(pt.tensor(X).to(self.wdro_loss_.rho)) # type: ignore
.squeeze(-1).detach().cpu().numpy()
)
return p
def predict_proba(self, X):
""" Robust prediction probability for classes -1 and +1.
Parameters
----------
X : array-like, shape (n_samples, n_features)
The input samples.
Returns
-------
p : ndarray, shape (n_samples,2)
The probability of each class for each of the samples.
"""
# Check is fit had been called
check_is_fitted(self, ['X_', 'y_'])
# Input validation
X = check_array(X)
p = expit(
self.wdro_loss_.primal_loss.transform(pt.from_numpy(X).to(self.wdro_loss_.rho)) # type: ignore
.squeeze(-1).detach().cpu().numpy()
)
return np.vstack((1 - p, p)).T
def predict(self, X):
""" Robust prediction.
Parameters
----------
X : array-like, shape (n_samples, n_features)
The input samples.
Returns
-------
y : ndarray, shape (n_samples,)
The label for each sample is the label of the closest sample
seen during fit.
"""
# Check is fit had been called
check_is_fitted(self, ['X_', 'y_'])
# Input validation
X = check_array(X)
X = np.array(X)
if isinstance(self.le_, LabelEncoder):
proba = self.predict_proba_2Class(X)
out = self.le_.inverse_transform((proba >= 0.5).astype('uint8'))
elif isinstance(self.le_, OneHotEncoder):
proba = self.predict_proba(X)
_p = proba >= np.max(proba, axis=1, keepdims=True)
out = self.le_.inverse_transform(
_p.astype('uint8')
)
else:
raise ValueError(
"The label encoder type {type(self.le_)} is not supported."
)
return out
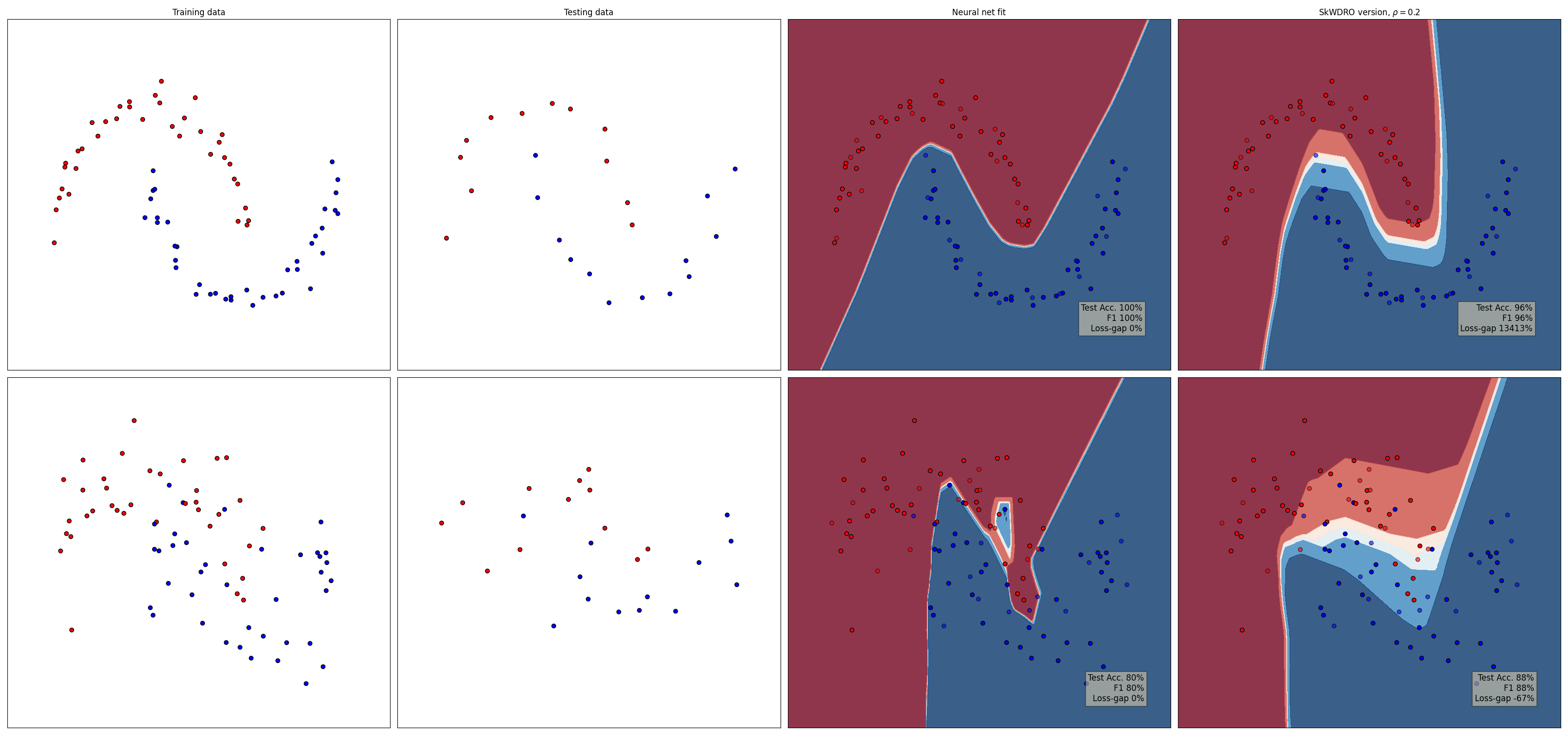
Setup#
Variance grows from (.05, .1) to (.1, .5), to try to trick the model.
n = 100 # Total number of samples
n_train = (3 * n) // 4 # Number of training samples
n_test = n - n_train # Number of test samples
sdevs = [(.05, .1), (.1, .5)]
# Create datasets with variance that is shifted at test time
datasets = []
for (sdev_1, sdev_2) in sdevs:
train_dataset = list(make_moons(n_samples=n_train)) # type: ignore
train_dataset[0] += np.array([sdev_1, sdev_2]) * np.random.randn(n_train, 2)
test_dataset = list(make_moons(n_samples=n_test)) # type: ignore
test_dataset[0] += np.array([sdev_2, sdev_1]) * np.random.randn(n_test, 2)
datasets.append((train_dataset, test_dataset))
WDRO classifiers#
We set two radii: 0 for ERM (the SkWDRO interfaces will handle it) and 0.2 is the radius picked for the robust classifier, which is the right one for the 2-Wasserstein distance between the variances we picked earlier.
rhos = [0, .2]
# Cost:
# t: torch backend
# NLC: norm cost that takes labels into account
# 2 2 : squared 2-norm
cost = f"t-NC-2-2"
# WDRO classifier
classifiers = [NeuralNetClassifier(rho=rho, cost=cost) for rho in rhos]
Make plot#
0%| | 0/2 [00:00<?, ?it/s]
0%| | 0/2 [00:00<?, ?it/s,
0.001/0.001
]
50%|█████ | 1/2 [00:00<00:00, 3.03it/s,
0.001/0.001
]
50%|█████ | 1/2 [00:01<00:00, 3.03it/s,
0.075/0.001
]
100%|██████████| 2/2 [00:01<00:00, 1.54it/s,
0.075/0.001
]
100%|██████████| 2/2 [00:01<00:00, 1.67it/s,
0.075/0.001
]
0%| | 0/2 [00:00<?, ?it/s]
0%| | 0/2 [00:00<?, ?it/s,
1.054/1.054
]
50%|█████ | 1/2 [00:00<00:00, 2.62it/s,
1.054/1.054
]
50%|█████ | 1/2 [00:01<00:00, 2.62it/s,
0.341/1.054
]
100%|██████████| 2/2 [00:01<00:00, 1.50it/s,
0.341/1.054
]
100%|██████████| 2/2 [00:01<00:00, 1.61it/s,
0.341/1.054
]
Total running time of the script: (0 minutes 2.720 seconds)