Note
Go to the end to download the full example code.
Comparison between some classification techniques#
Classification problems are all written in a simple way, as explained in other tutorials.
We consider a simple classification problem to highlight the possibility of classifying samples with various methods, not to showcase their specificities.
We start with logistic regression, which is by far the most covered example of the library, and then present some minor modifications we can make to catter to some other classification techniques. All of those losses are taken from [1].
Hint
All those models are optimized in the default library settings, which represent uncertainty sets of type Wasserstein-2-2 (regularized), even though some of them are Lipschitz and thus may benefit from lower-order neighborhoods.
from sklearn.datasets import make_blobs
import torch as pt
import torch.nn as nn
from tqdm import tqdm
from skwdro.torch import robustify
from skwdro.linear_models._logistic_regression import BiDiffSoftMarginLoss
from skwdro.solvers.oracle_torch import DualLoss
from examples.custom_models.utils.plotting import plot_decision_boundary
Problem setup#
Training loop#
Define a function to train a model so that we can reuse it in various settings
def train(dual_loss: DualLoss, dataset: tuple[pt.Tensor, pt.Tensor], epochs: int=100):
lbfgs = pt.optim.LBFGS(dual_loss.parameters()) # LBFGS is used to optimize thanks to the nature of the problem
def closure(): # Closure for the LBFGS solver
lbfgs.zero_grad()
loss = dual_loss(*dataset).mean()
loss.backward()
return loss
pbar = tqdm(range(epochs))
# Every now and then, try to rectify the dual parameter (e.g. once per epoch).
dual_loss.get_initial_guess_at_dual(*dataset)
for _ in pbar:
lbfgs.step(closure)
if dual_loss.lam <= 0.:
dual_loss._lam.requires_grad_(False)
dual_loss._lam.mul_(0.)
dual_loss._lam.requires_grad_(True)
pbar.set_postfix({"lambda": f"{dual_loss.lam.item():.2f}"})
t = dual_loss.primal_loss.transform
assert isinstance(t, nn.Linear)
return t
First model: logistic regression#
The loss function \(\ell\) for this problem is the “soft-margin” function, a softened version of the hinge classification loss that we will see in the next example.
Note
The native torch.nn.SoftMarginLoss implementation of the
desired loss could have been satisfactory, but importantly it is not
differentiable in its label argument.
This is why we implement our own version of the “bi-differentiable”
soft-margin loss
skwdro.linear_models._logistic_regression.BiDiffSoftMarginLoss.
First model: Training#
model1 = train(dro_model, (X, y)) # type: ignore
model1.eval() # type: ignore
0%| | 0/100 [00:00<?, ?it/s]
0%| | 0/100 [00:00<?, ?it/s, lambda=-0.00]
0%| | 0/100 [00:00<?, ?it/s, lambda=-0.00]
0%| | 0/100 [00:00<?, ?it/s, lambda=-0.00]
0%| | 0/100 [00:00<?, ?it/s, lambda=-0.00]
4%|▍ | 4/100 [00:00<00:02, 32.90it/s, lambda=-0.00]
4%|▍ | 4/100 [00:00<00:02, 32.90it/s, lambda=-0.00]
4%|▍ | 4/100 [00:00<00:02, 32.90it/s, lambda=-0.00]
4%|▍ | 4/100 [00:00<00:02, 32.90it/s, lambda=-0.00]
4%|▍ | 4/100 [00:00<00:02, 32.90it/s, lambda=-0.00]
8%|▊ | 8/100 [00:00<00:02, 32.48it/s, lambda=-0.00]
8%|▊ | 8/100 [00:00<00:02, 32.48it/s, lambda=-0.00]
8%|▊ | 8/100 [00:00<00:02, 32.48it/s, lambda=-0.00]
8%|▊ | 8/100 [00:00<00:02, 32.48it/s, lambda=-0.00]
8%|▊ | 8/100 [00:00<00:02, 32.48it/s, lambda=-0.00]
12%|█▏ | 12/100 [00:00<00:02, 32.02it/s, lambda=-0.00]
12%|█▏ | 12/100 [00:00<00:02, 32.02it/s, lambda=-0.00]
12%|█▏ | 12/100 [00:00<00:02, 32.02it/s, lambda=-0.00]
12%|█▏ | 12/100 [00:00<00:02, 32.02it/s, lambda=-0.00]
12%|█▏ | 12/100 [00:00<00:02, 32.02it/s, lambda=-0.00]
16%|█▌ | 16/100 [00:00<00:02, 31.46it/s, lambda=-0.00]
16%|█▌ | 16/100 [00:00<00:02, 31.46it/s, lambda=-0.00]
16%|█▌ | 16/100 [00:00<00:02, 31.46it/s, lambda=-0.00]
16%|█▌ | 16/100 [00:00<00:02, 31.46it/s, lambda=-0.00]
16%|█▌ | 16/100 [00:00<00:02, 31.46it/s, lambda=-0.00]
20%|██ | 20/100 [00:00<00:02, 30.85it/s, lambda=-0.00]
20%|██ | 20/100 [00:00<00:02, 30.85it/s, lambda=-0.00]
20%|██ | 20/100 [00:00<00:02, 30.85it/s, lambda=-0.00]
20%|██ | 20/100 [00:00<00:02, 30.85it/s, lambda=-0.00]
20%|██ | 20/100 [00:00<00:02, 30.85it/s, lambda=-0.00]
24%|██▍ | 24/100 [00:00<00:02, 30.14it/s, lambda=-0.00]
24%|██▍ | 24/100 [00:00<00:02, 30.14it/s, lambda=-0.00]
24%|██▍ | 24/100 [00:00<00:02, 30.14it/s, lambda=-0.00]
24%|██▍ | 24/100 [00:00<00:02, 30.14it/s, lambda=-0.00]
24%|██▍ | 24/100 [00:00<00:02, 30.14it/s, lambda=-0.00]
28%|██▊ | 28/100 [00:00<00:02, 29.37it/s, lambda=-0.00]
28%|██▊ | 28/100 [00:00<00:02, 29.37it/s, lambda=-0.00]
28%|██▊ | 28/100 [00:00<00:02, 29.37it/s, lambda=-0.00]
28%|██▊ | 28/100 [00:01<00:02, 29.37it/s, lambda=-0.00]
31%|███ | 31/100 [00:01<00:02, 28.90it/s, lambda=-0.00]
31%|███ | 31/100 [00:01<00:02, 28.90it/s, lambda=-0.00]
31%|███ | 31/100 [00:01<00:02, 28.90it/s, lambda=-0.00]
31%|███ | 31/100 [00:01<00:02, 28.90it/s, lambda=-0.00]
34%|███▍ | 34/100 [00:01<00:02, 28.43it/s, lambda=-0.00]
34%|███▍ | 34/100 [00:01<00:02, 28.43it/s, lambda=-0.00]
34%|███▍ | 34/100 [00:01<00:02, 28.43it/s, lambda=-0.00]
34%|███▍ | 34/100 [00:01<00:02, 28.43it/s, lambda=-0.00]
37%|███▋ | 37/100 [00:01<00:02, 27.95it/s, lambda=-0.00]
37%|███▋ | 37/100 [00:01<00:02, 27.95it/s, lambda=-0.00]
37%|███▋ | 37/100 [00:01<00:02, 27.95it/s, lambda=-0.00]
37%|███▋ | 37/100 [00:01<00:02, 27.95it/s, lambda=-0.00]
40%|████ | 40/100 [00:01<00:02, 27.48it/s, lambda=-0.00]
40%|████ | 40/100 [00:01<00:02, 27.48it/s, lambda=-0.00]
40%|████ | 40/100 [00:01<00:02, 27.48it/s, lambda=-0.00]
40%|████ | 40/100 [00:01<00:02, 27.48it/s, lambda=-0.00]
43%|████▎ | 43/100 [00:01<00:02, 26.99it/s, lambda=-0.00]
43%|████▎ | 43/100 [00:01<00:02, 26.99it/s, lambda=-0.00]
43%|████▎ | 43/100 [00:01<00:02, 26.99it/s, lambda=-0.00]
43%|████▎ | 43/100 [00:01<00:02, 26.99it/s, lambda=-0.00]
46%|████▌ | 46/100 [00:01<00:02, 26.54it/s, lambda=-0.00]
46%|████▌ | 46/100 [00:01<00:02, 26.54it/s, lambda=-0.00]
46%|████▌ | 46/100 [00:01<00:02, 26.54it/s, lambda=-0.00]
46%|████▌ | 46/100 [00:01<00:02, 26.54it/s, lambda=-0.00]
49%|████▉ | 49/100 [00:01<00:01, 26.10it/s, lambda=-0.00]
49%|████▉ | 49/100 [00:01<00:01, 26.10it/s, lambda=-0.00]
49%|████▉ | 49/100 [00:01<00:01, 26.10it/s, lambda=-0.00]
49%|████▉ | 49/100 [00:01<00:01, 26.10it/s, lambda=-0.00]
52%|█████▏ | 52/100 [00:01<00:01, 25.64it/s, lambda=-0.00]
52%|█████▏ | 52/100 [00:01<00:01, 25.64it/s, lambda=-0.00]
52%|█████▏ | 52/100 [00:01<00:01, 25.64it/s, lambda=-0.00]
52%|█████▏ | 52/100 [00:01<00:01, 25.64it/s, lambda=-0.00]
55%|█████▌ | 55/100 [00:01<00:01, 25.19it/s, lambda=-0.00]
55%|█████▌ | 55/100 [00:02<00:01, 25.19it/s, lambda=-0.00]
55%|█████▌ | 55/100 [00:02<00:01, 25.19it/s, lambda=-0.00]
55%|█████▌ | 55/100 [00:02<00:01, 25.19it/s, lambda=-0.00]
58%|█████▊ | 58/100 [00:02<00:01, 24.79it/s, lambda=-0.00]
58%|█████▊ | 58/100 [00:02<00:01, 24.79it/s, lambda=-0.00]
58%|█████▊ | 58/100 [00:02<00:01, 24.79it/s, lambda=-0.00]
58%|█████▊ | 58/100 [00:02<00:01, 24.79it/s, lambda=-0.00]
61%|██████ | 61/100 [00:02<00:01, 24.38it/s, lambda=-0.00]
61%|██████ | 61/100 [00:02<00:01, 24.38it/s, lambda=-0.00]
61%|██████ | 61/100 [00:02<00:01, 24.38it/s, lambda=-0.00]
61%|██████ | 61/100 [00:02<00:01, 24.38it/s, lambda=-0.00]
64%|██████▍ | 64/100 [00:02<00:01, 24.03it/s, lambda=-0.00]
64%|██████▍ | 64/100 [00:02<00:01, 24.03it/s, lambda=-0.00]
64%|██████▍ | 64/100 [00:02<00:01, 24.03it/s, lambda=-0.00]
64%|██████▍ | 64/100 [00:02<00:01, 24.03it/s, lambda=-0.00]
67%|██████▋ | 67/100 [00:02<00:01, 23.67it/s, lambda=-0.00]
67%|██████▋ | 67/100 [00:02<00:01, 23.67it/s, lambda=-0.00]
67%|██████▋ | 67/100 [00:02<00:01, 23.67it/s, lambda=-0.00]
67%|██████▋ | 67/100 [00:02<00:01, 23.67it/s, lambda=-0.00]
70%|███████ | 70/100 [00:02<00:01, 23.33it/s, lambda=-0.00]
70%|███████ | 70/100 [00:02<00:01, 23.33it/s, lambda=-0.00]
70%|███████ | 70/100 [00:02<00:01, 23.33it/s, lambda=-0.00]
70%|███████ | 70/100 [00:02<00:01, 23.33it/s, lambda=-0.00]
73%|███████▎ | 73/100 [00:02<00:01, 22.99it/s, lambda=-0.00]
73%|███████▎ | 73/100 [00:02<00:01, 22.99it/s, lambda=-0.00]
73%|███████▎ | 73/100 [00:02<00:01, 22.99it/s, lambda=-0.00]
73%|███████▎ | 73/100 [00:02<00:01, 22.99it/s, lambda=-0.00]
76%|███████▌ | 76/100 [00:02<00:01, 22.66it/s, lambda=-0.00]
76%|███████▌ | 76/100 [00:02<00:01, 22.66it/s, lambda=-0.00]
76%|███████▌ | 76/100 [00:02<00:01, 22.66it/s, lambda=-0.00]
76%|███████▌ | 76/100 [00:03<00:01, 22.66it/s, lambda=-0.00]
79%|███████▉ | 79/100 [00:03<00:00, 22.32it/s, lambda=-0.00]
79%|███████▉ | 79/100 [00:03<00:00, 22.32it/s, lambda=-0.00]
79%|███████▉ | 79/100 [00:03<00:00, 22.32it/s, lambda=-0.00]
79%|███████▉ | 79/100 [00:03<00:00, 22.32it/s, lambda=-0.00]
82%|████████▏ | 82/100 [00:03<00:00, 21.99it/s, lambda=-0.00]
82%|████████▏ | 82/100 [00:03<00:00, 21.99it/s, lambda=-0.00]
82%|████████▏ | 82/100 [00:03<00:00, 21.99it/s, lambda=-0.00]
82%|████████▏ | 82/100 [00:03<00:00, 21.99it/s, lambda=-0.00]
85%|████████▌ | 85/100 [00:03<00:00, 21.66it/s, lambda=-0.00]
85%|████████▌ | 85/100 [00:03<00:00, 21.66it/s, lambda=-0.00]
85%|████████▌ | 85/100 [00:03<00:00, 21.66it/s, lambda=-0.00]
85%|████████▌ | 85/100 [00:03<00:00, 21.66it/s, lambda=-0.00]
88%|████████▊ | 88/100 [00:03<00:00, 21.44it/s, lambda=-0.00]
88%|████████▊ | 88/100 [00:03<00:00, 21.44it/s, lambda=-0.00]
88%|████████▊ | 88/100 [00:03<00:00, 21.44it/s, lambda=-0.00]
88%|████████▊ | 88/100 [00:03<00:00, 21.44it/s, lambda=-0.00]
91%|█████████ | 91/100 [00:03<00:00, 21.30it/s, lambda=-0.00]
91%|█████████ | 91/100 [00:03<00:00, 21.30it/s, lambda=-0.00]
91%|█████████ | 91/100 [00:03<00:00, 21.30it/s, lambda=-0.00]
91%|█████████ | 91/100 [00:03<00:00, 21.30it/s, lambda=-0.00]
94%|█████████▍| 94/100 [00:03<00:00, 21.19it/s, lambda=-0.00]
94%|█████████▍| 94/100 [00:03<00:00, 21.19it/s, lambda=-0.00]
94%|█████████▍| 94/100 [00:03<00:00, 21.19it/s, lambda=-0.00]
94%|█████████▍| 94/100 [00:03<00:00, 21.19it/s, lambda=-0.00]
97%|█████████▋| 97/100 [00:03<00:00, 21.11it/s, lambda=-0.00]
97%|█████████▋| 97/100 [00:03<00:00, 21.11it/s, lambda=-0.00]
97%|█████████▋| 97/100 [00:03<00:00, 21.11it/s, lambda=-0.00]
97%|█████████▋| 97/100 [00:04<00:00, 21.11it/s, lambda=-0.00]
100%|██████████| 100/100 [00:04<00:00, 21.07it/s, lambda=-0.00]
100%|██████████| 100/100 [00:04<00:00, 24.87it/s, lambda=-0.00]
Linear(in_features=2, out_features=1, bias=True)
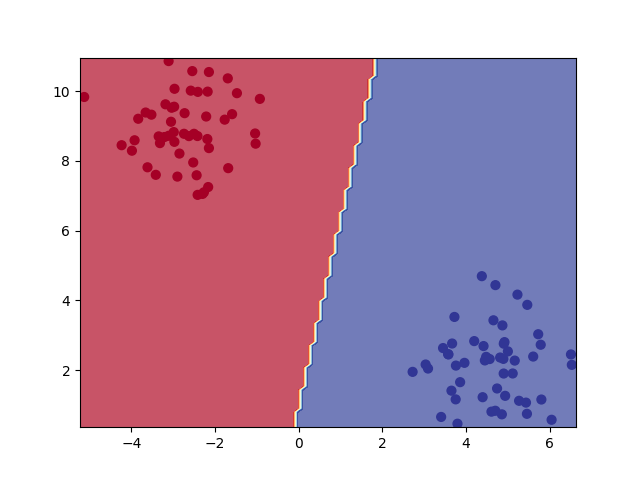
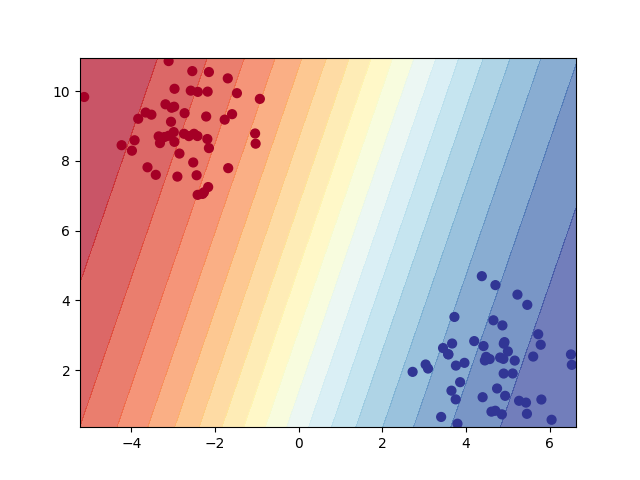
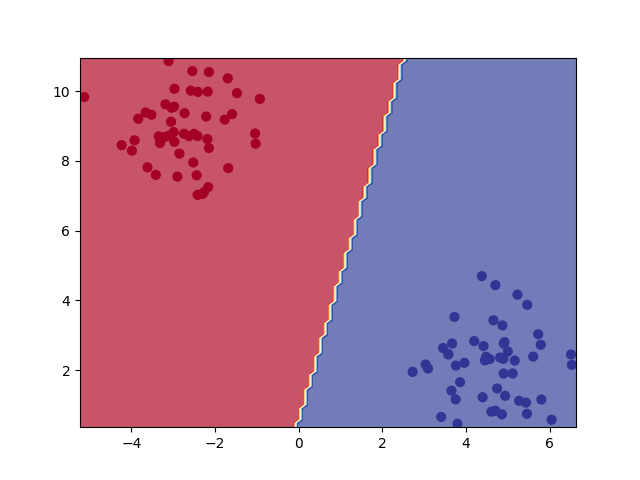
First model: Results#
plot_decision_boundary(model1, X, y, n_levels=20)
Second model: SVM (primal)#
The classical Support Vector Machine model, with the Hinge loss and linear kernel, can be implemented in various ways. The one favored by scikit-learn e.g., when no ridge regularization is used, is as follows (see this remark):
In our case, we suppose that the method is in the “big-data-low-dim” regime, in which using the Kernel trick would be detrimental. In this setting, the implementation is straightforward.
Second model: Training#
model2 = train(dro_model, (X, y), epochs=50) # type: ignore
model2.eval() # type: ignore
0%| | 0/50 [00:00<?, ?it/s]
0%| | 0/50 [00:00<?, ?it/s, lambda=203.41]
0%| | 0/50 [00:00<?, ?it/s, lambda=203.41]
0%| | 0/50 [00:00<?, ?it/s, lambda=203.41]
0%| | 0/50 [00:00<?, ?it/s, lambda=203.41]
0%| | 0/50 [00:00<?, ?it/s, lambda=203.41]
0%| | 0/50 [00:00<?, ?it/s, lambda=203.41]
0%| | 0/50 [00:00<?, ?it/s, lambda=203.41]
0%| | 0/50 [00:00<?, ?it/s, lambda=203.41]
0%| | 0/50 [00:00<?, ?it/s, lambda=203.41]
0%| | 0/50 [00:00<?, ?it/s, lambda=203.41]
0%| | 0/50 [00:00<?, ?it/s, lambda=203.41]
0%| | 0/50 [00:00<?, ?it/s, lambda=203.41]
24%|██▍ | 12/50 [00:00<00:00, 116.66it/s, lambda=203.41]
24%|██▍ | 12/50 [00:00<00:00, 116.66it/s, lambda=203.41]
24%|██▍ | 12/50 [00:00<00:00, 116.66it/s, lambda=203.41]
24%|██▍ | 12/50 [00:00<00:00, 116.66it/s, lambda=203.41]
24%|██▍ | 12/50 [00:00<00:00, 116.66it/s, lambda=203.41]
24%|██▍ | 12/50 [00:00<00:00, 116.66it/s, lambda=203.41]
24%|██▍ | 12/50 [00:00<00:00, 116.66it/s, lambda=203.41]
24%|██▍ | 12/50 [00:00<00:00, 116.66it/s, lambda=203.41]
24%|██▍ | 12/50 [00:00<00:00, 116.66it/s, lambda=203.41]
24%|██▍ | 12/50 [00:00<00:00, 116.66it/s, lambda=203.41]
24%|██▍ | 12/50 [00:00<00:00, 116.66it/s, lambda=203.41]
24%|██▍ | 12/50 [00:00<00:00, 116.66it/s, lambda=203.41]
24%|██▍ | 12/50 [00:00<00:00, 116.66it/s, lambda=203.41]
24%|██▍ | 12/50 [00:00<00:00, 116.66it/s, lambda=203.41]
24%|██▍ | 12/50 [00:00<00:00, 116.66it/s, lambda=203.41]
52%|█████▏ | 26/50 [00:00<00:00, 124.65it/s, lambda=203.41]
52%|█████▏ | 26/50 [00:00<00:00, 124.65it/s, lambda=203.41]
52%|█████▏ | 26/50 [00:00<00:00, 124.65it/s, lambda=203.41]
52%|█████▏ | 26/50 [00:00<00:00, 124.65it/s, lambda=203.41]
52%|█████▏ | 26/50 [00:00<00:00, 124.65it/s, lambda=203.41]
52%|█████▏ | 26/50 [00:00<00:00, 124.65it/s, lambda=203.41]
52%|█████▏ | 26/50 [00:00<00:00, 124.65it/s, lambda=203.41]
52%|█████▏ | 26/50 [00:00<00:00, 124.65it/s, lambda=203.41]
52%|█████▏ | 26/50 [00:00<00:00, 124.65it/s, lambda=203.41]
52%|█████▏ | 26/50 [00:00<00:00, 124.65it/s, lambda=203.41]
52%|█████▏ | 26/50 [00:00<00:00, 124.65it/s, lambda=203.41]
52%|█████▏ | 26/50 [00:00<00:00, 124.65it/s, lambda=203.41]
52%|█████▏ | 26/50 [00:00<00:00, 124.65it/s, lambda=203.41]
52%|█████▏ | 26/50 [00:00<00:00, 124.65it/s, lambda=203.41]
78%|███████▊ | 39/50 [00:00<00:00, 120.18it/s, lambda=203.41]
78%|███████▊ | 39/50 [00:00<00:00, 120.18it/s, lambda=203.41]
78%|███████▊ | 39/50 [00:00<00:00, 120.18it/s, lambda=203.40]
78%|███████▊ | 39/50 [00:00<00:00, 120.18it/s, lambda=203.40]
78%|███████▊ | 39/50 [00:00<00:00, 120.18it/s, lambda=203.40]
78%|███████▊ | 39/50 [00:00<00:00, 120.18it/s, lambda=203.40]
78%|███████▊ | 39/50 [00:00<00:00, 120.18it/s, lambda=203.40]
78%|███████▊ | 39/50 [00:00<00:00, 120.18it/s, lambda=203.40]
78%|███████▊ | 39/50 [00:00<00:00, 120.18it/s, lambda=203.40]
78%|███████▊ | 39/50 [00:00<00:00, 120.18it/s, lambda=203.40]
78%|███████▊ | 39/50 [00:00<00:00, 120.18it/s, lambda=203.40]
78%|███████▊ | 39/50 [00:00<00:00, 120.18it/s, lambda=203.40]
100%|██████████| 50/50 [00:00<00:00, 121.15it/s, lambda=203.40]
Linear(in_features=2, out_features=1, bias=True)
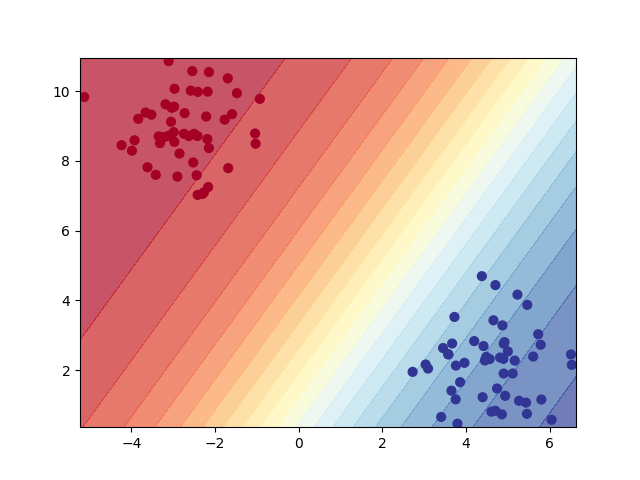
Second model: Results#
plot_decision_boundary(model2, X, y, n_levels=20)
Third model: Soft-SVM#
This example covers nothing but an extension of the classical linear SVM, with a smoothed version of the Hinge loss presented above:
We solve it in exactly the same way.
class SmoothHingeLoss(nn.Module):
reduction: str = 'none'
gamma: float = 1.0
def __init__(self, gamma=1.):
super().__init__()
self.gamma = gamma
def forward(self, x, y):
a = y*x
quad_part = (.5 / self.gamma) * nn.functional.relu(1. - a)**2
lin_part = 1. - 0.5 * self.gamma - a
dec = (a >= 1. - self.gamma).detach()
return quad_part * dec.float() + lin_part * pt.logical_not(dec).float()
model = nn.Linear(2, 1).to(X)
loss = SmoothHingeLoss()
dro_model = robustify(
loss,
model,
radius,
X, y,
seed=SEED,
imp_samp=False
)
Third model: Training#
model3 = train(dro_model, (X, y), epochs=50) # type: ignore
model3.eval() # type: ignore
0%| | 0/50 [00:00<?, ?it/s]
0%| | 0/50 [00:00<?, ?it/s, lambda=203.18]
0%| | 0/50 [00:00<?, ?it/s, lambda=-0.00]
0%| | 0/50 [00:00<?, ?it/s, lambda=-0.00]
0%| | 0/50 [00:00<?, ?it/s, lambda=-0.00]
8%|▊ | 4/50 [00:00<00:01, 31.58it/s, lambda=-0.00]
8%|▊ | 4/50 [00:00<00:01, 31.58it/s, lambda=-0.00]
8%|▊ | 4/50 [00:00<00:01, 31.58it/s, lambda=-0.00]
8%|▊ | 4/50 [00:00<00:01, 31.58it/s, lambda=-0.00]
8%|▊ | 4/50 [00:00<00:01, 31.58it/s, lambda=-0.00]
16%|█▌ | 8/50 [00:00<00:01, 30.89it/s, lambda=-0.00]
16%|█▌ | 8/50 [00:00<00:01, 30.89it/s, lambda=-0.00]
16%|█▌ | 8/50 [00:00<00:01, 30.89it/s, lambda=-0.00]
16%|█▌ | 8/50 [00:00<00:01, 30.89it/s, lambda=-0.00]
16%|█▌ | 8/50 [00:00<00:01, 30.89it/s, lambda=-0.00]
24%|██▍ | 12/50 [00:00<00:01, 30.32it/s, lambda=-0.00]
24%|██▍ | 12/50 [00:00<00:01, 30.32it/s, lambda=-0.00]
24%|██▍ | 12/50 [00:00<00:01, 30.32it/s, lambda=-0.00]
24%|██▍ | 12/50 [00:00<00:01, 30.32it/s, lambda=-0.00]
24%|██▍ | 12/50 [00:00<00:01, 30.32it/s, lambda=-0.00]
32%|███▏ | 16/50 [00:00<00:01, 29.76it/s, lambda=-0.00]
32%|███▏ | 16/50 [00:00<00:01, 29.76it/s, lambda=-0.00]
32%|███▏ | 16/50 [00:00<00:01, 29.76it/s, lambda=-0.00]
32%|███▏ | 16/50 [00:00<00:01, 29.76it/s, lambda=-0.00]
38%|███▊ | 19/50 [00:00<00:01, 29.31it/s, lambda=-0.00]
38%|███▊ | 19/50 [00:00<00:01, 29.31it/s, lambda=-0.00]
38%|███▊ | 19/50 [00:00<00:01, 29.31it/s, lambda=-0.00]
38%|███▊ | 19/50 [00:00<00:01, 29.31it/s, lambda=-0.00]
44%|████▍ | 22/50 [00:00<00:00, 28.81it/s, lambda=-0.00]
44%|████▍ | 22/50 [00:00<00:00, 28.81it/s, lambda=-0.00]
44%|████▍ | 22/50 [00:00<00:00, 28.81it/s, lambda=-0.00]
44%|████▍ | 22/50 [00:00<00:00, 28.81it/s, lambda=-0.00]
50%|█████ | 25/50 [00:00<00:00, 28.34it/s, lambda=-0.00]
50%|█████ | 25/50 [00:00<00:00, 28.34it/s, lambda=-0.00]
50%|█████ | 25/50 [00:00<00:00, 28.34it/s, lambda=-0.00]
50%|█████ | 25/50 [00:00<00:00, 28.34it/s, lambda=-0.00]
56%|█████▌ | 28/50 [00:00<00:00, 27.87it/s, lambda=-0.00]
56%|█████▌ | 28/50 [00:01<00:00, 27.87it/s, lambda=-0.00]
56%|█████▌ | 28/50 [00:01<00:00, 27.87it/s, lambda=-0.00]
56%|█████▌ | 28/50 [00:01<00:00, 27.87it/s, lambda=-0.00]
62%|██████▏ | 31/50 [00:01<00:00, 27.40it/s, lambda=-0.00]
62%|██████▏ | 31/50 [00:01<00:00, 27.40it/s, lambda=-0.00]
62%|██████▏ | 31/50 [00:01<00:00, 27.40it/s, lambda=-0.00]
62%|██████▏ | 31/50 [00:01<00:00, 27.40it/s, lambda=-0.00]
68%|██████▊ | 34/50 [00:01<00:00, 26.95it/s, lambda=-0.00]
68%|██████▊ | 34/50 [00:01<00:00, 26.95it/s, lambda=-0.00]
68%|██████▊ | 34/50 [00:01<00:00, 26.95it/s, lambda=-0.00]
68%|██████▊ | 34/50 [00:01<00:00, 26.95it/s, lambda=-0.00]
74%|███████▍ | 37/50 [00:01<00:00, 26.46it/s, lambda=-0.00]
74%|███████▍ | 37/50 [00:01<00:00, 26.46it/s, lambda=-0.00]
74%|███████▍ | 37/50 [00:01<00:00, 26.46it/s, lambda=-0.00]
74%|███████▍ | 37/50 [00:01<00:00, 26.46it/s, lambda=-0.00]
80%|████████ | 40/50 [00:01<00:00, 26.00it/s, lambda=-0.00]
80%|████████ | 40/50 [00:01<00:00, 26.00it/s, lambda=-0.00]
80%|████████ | 40/50 [00:01<00:00, 26.00it/s, lambda=-0.00]
80%|████████ | 40/50 [00:01<00:00, 26.00it/s, lambda=-0.00]
86%|████████▌ | 43/50 [00:01<00:00, 25.52it/s, lambda=-0.00]
86%|████████▌ | 43/50 [00:01<00:00, 25.52it/s, lambda=-0.00]
86%|████████▌ | 43/50 [00:01<00:00, 25.52it/s, lambda=-0.00]
86%|████████▌ | 43/50 [00:01<00:00, 25.52it/s, lambda=-0.00]
92%|█████████▏| 46/50 [00:01<00:00, 25.08it/s, lambda=-0.00]
92%|█████████▏| 46/50 [00:01<00:00, 25.08it/s, lambda=-0.00]
92%|█████████▏| 46/50 [00:01<00:00, 25.08it/s, lambda=-0.00]
92%|█████████▏| 46/50 [00:01<00:00, 25.08it/s, lambda=-0.00]
98%|█████████▊| 49/50 [00:01<00:00, 24.72it/s, lambda=-0.00]
98%|█████████▊| 49/50 [00:01<00:00, 24.72it/s, lambda=-0.00]
100%|██████████| 50/50 [00:01<00:00, 27.03it/s, lambda=-0.00]
Linear(in_features=2, out_features=1, bias=True)
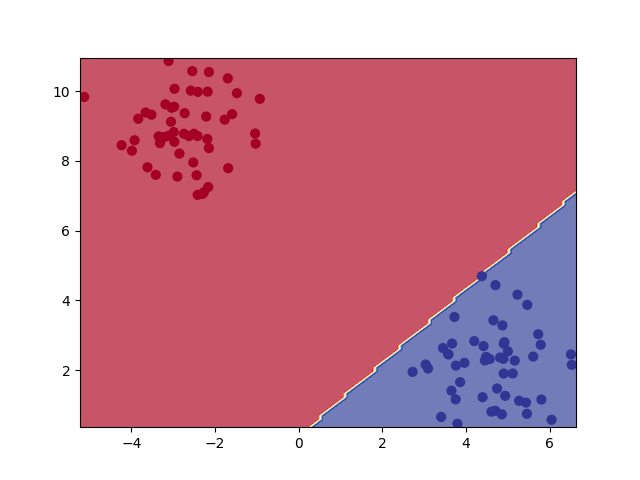
Third model: Results#
plot_decision_boundary(model3, X, y, n_levels=20)
Fourth model: The Perceptron#
This example covers the classical perceptron for classification task.
We solve it in exactly the same way.
Fourth model: Training#
model4 = train(dro_model, (X, y), epochs=50) # type: ignore
model4.eval() # type: ignore
0%| | 0/50 [00:00<?, ?it/s]
0%| | 0/50 [00:00<?, ?it/s, lambda=203.41]
0%| | 0/50 [00:00<?, ?it/s, lambda=203.41]
0%| | 0/50 [00:00<?, ?it/s, lambda=203.41]
0%| | 0/50 [00:00<?, ?it/s, lambda=203.41]
0%| | 0/50 [00:00<?, ?it/s, lambda=203.41]
0%| | 0/50 [00:00<?, ?it/s, lambda=203.41]
0%| | 0/50 [00:00<?, ?it/s, lambda=203.41]
0%| | 0/50 [00:00<?, ?it/s, lambda=203.41]
0%| | 0/50 [00:00<?, ?it/s, lambda=203.41]
0%| | 0/50 [00:00<?, ?it/s, lambda=203.41]
0%| | 0/50 [00:00<?, ?it/s, lambda=203.41]
0%| | 0/50 [00:00<?, ?it/s, lambda=203.41]
24%|██▍ | 12/50 [00:00<00:00, 118.40it/s, lambda=203.41]
24%|██▍ | 12/50 [00:00<00:00, 118.40it/s, lambda=203.41]
24%|██▍ | 12/50 [00:00<00:00, 118.40it/s, lambda=203.41]
24%|██▍ | 12/50 [00:00<00:00, 118.40it/s, lambda=203.41]
24%|██▍ | 12/50 [00:00<00:00, 118.40it/s, lambda=203.41]
24%|██▍ | 12/50 [00:00<00:00, 118.40it/s, lambda=203.41]
24%|██▍ | 12/50 [00:00<00:00, 118.40it/s, lambda=203.41]
24%|██▍ | 12/50 [00:00<00:00, 118.40it/s, lambda=203.41]
24%|██▍ | 12/50 [00:00<00:00, 118.40it/s, lambda=203.41]
24%|██▍ | 12/50 [00:00<00:00, 118.40it/s, lambda=203.41]
24%|██▍ | 12/50 [00:00<00:00, 118.40it/s, lambda=203.41]
24%|██▍ | 12/50 [00:00<00:00, 118.40it/s, lambda=203.41]
24%|██▍ | 12/50 [00:00<00:00, 118.40it/s, lambda=203.41]
24%|██▍ | 12/50 [00:00<00:00, 118.40it/s, lambda=203.41]
24%|██▍ | 12/50 [00:00<00:00, 118.40it/s, lambda=203.41]
52%|█████▏ | 26/50 [00:00<00:00, 127.21it/s, lambda=203.41]
52%|█████▏ | 26/50 [00:00<00:00, 127.21it/s, lambda=203.41]
52%|█████▏ | 26/50 [00:00<00:00, 127.21it/s, lambda=203.41]
52%|█████▏ | 26/50 [00:00<00:00, 127.21it/s, lambda=203.41]
52%|█████▏ | 26/50 [00:00<00:00, 127.21it/s, lambda=203.41]
52%|█████▏ | 26/50 [00:00<00:00, 127.21it/s, lambda=203.41]
52%|█████▏ | 26/50 [00:00<00:00, 127.21it/s, lambda=203.41]
52%|█████▏ | 26/50 [00:00<00:00, 127.21it/s, lambda=203.41]
52%|█████▏ | 26/50 [00:00<00:00, 127.21it/s, lambda=203.41]
52%|█████▏ | 26/50 [00:00<00:00, 127.21it/s, lambda=203.41]
52%|█████▏ | 26/50 [00:00<00:00, 127.21it/s, lambda=203.41]
52%|█████▏ | 26/50 [00:00<00:00, 127.21it/s, lambda=203.41]
52%|█████▏ | 26/50 [00:00<00:00, 127.21it/s, lambda=203.41]
52%|█████▏ | 26/50 [00:00<00:00, 127.21it/s, lambda=203.41]
78%|███████▊ | 39/50 [00:00<00:00, 123.06it/s, lambda=203.41]
78%|███████▊ | 39/50 [00:00<00:00, 123.06it/s, lambda=203.41]
78%|███████▊ | 39/50 [00:00<00:00, 123.06it/s, lambda=203.40]
78%|███████▊ | 39/50 [00:00<00:00, 123.06it/s, lambda=203.40]
78%|███████▊ | 39/50 [00:00<00:00, 123.06it/s, lambda=203.40]
78%|███████▊ | 39/50 [00:00<00:00, 123.06it/s, lambda=203.40]
78%|███████▊ | 39/50 [00:00<00:00, 123.06it/s, lambda=203.40]
78%|███████▊ | 39/50 [00:00<00:00, 123.06it/s, lambda=203.40]
78%|███████▊ | 39/50 [00:00<00:00, 123.06it/s, lambda=203.40]
78%|███████▊ | 39/50 [00:00<00:00, 123.06it/s, lambda=203.40]
78%|███████▊ | 39/50 [00:00<00:00, 123.06it/s, lambda=203.40]
78%|███████▊ | 39/50 [00:00<00:00, 123.06it/s, lambda=203.40]
100%|██████████| 50/50 [00:00<00:00, 124.04it/s, lambda=203.40]
Linear(in_features=2, out_features=1, bias=True)
Fourth model: Results#
plot_decision_boundary(model4, X, y, n_levels=20)

Fifth model: Quadratic margin loss#
This example covers a margin loss that is modeled as a quadratic form. It is substantially different from the other losses because it forces the cross-product \(\xi^\texttt{labels}\langle\theta\mid\xi^\texttt{input}\rangle\) to be equal to one precisely, not to be greater to a margin like most others.
Fifth model: Training#
model5 = train(dro_model, (X, y), epochs=50) # type: ignore
model5.eval() # type: ignore
0%| | 0/50 [00:00<?, ?it/s]
0%| | 0/50 [00:00<?, ?it/s, lambda=2831.02]
0%| | 0/50 [00:00<?, ?it/s, lambda=2831.02]
0%| | 0/50 [00:00<?, ?it/s, lambda=2831.02]
0%| | 0/50 [00:00<?, ?it/s, lambda=2831.02]
0%| | 0/50 [00:00<?, ?it/s, lambda=2831.02]
0%| | 0/50 [00:00<?, ?it/s, lambda=2831.02]
0%| | 0/50 [00:00<?, ?it/s, lambda=2831.02]
0%| | 0/50 [00:00<?, ?it/s, lambda=2831.02]
0%| | 0/50 [00:00<?, ?it/s, lambda=2831.02]
0%| | 0/50 [00:00<?, ?it/s, lambda=2831.02]
0%| | 0/50 [00:00<?, ?it/s, lambda=2831.02]
0%| | 0/50 [00:00<?, ?it/s, lambda=2831.02]
0%| | 0/50 [00:00<?, ?it/s, lambda=2831.02]
0%| | 0/50 [00:00<?, ?it/s, lambda=2831.02]
0%| | 0/50 [00:00<?, ?it/s, lambda=2831.02]
0%| | 0/50 [00:00<?, ?it/s, lambda=2831.02]
0%| | 0/50 [00:00<?, ?it/s, lambda=2831.02]
0%| | 0/50 [00:00<?, ?it/s, lambda=2831.02]
0%| | 0/50 [00:00<?, ?it/s, lambda=2831.02]
0%| | 0/50 [00:00<?, ?it/s, lambda=2831.02]
0%| | 0/50 [00:00<?, ?it/s, lambda=2831.02]
0%| | 0/50 [00:00<?, ?it/s, lambda=2831.02]
0%| | 0/50 [00:00<?, ?it/s, lambda=2831.02]
0%| | 0/50 [00:00<?, ?it/s, lambda=2831.02]
0%| | 0/50 [00:00<?, ?it/s, lambda=2831.02]
0%| | 0/50 [00:00<?, ?it/s, lambda=2831.02]
52%|█████▏ | 26/50 [00:00<00:00, 259.95it/s, lambda=2831.02]
52%|█████▏ | 26/50 [00:00<00:00, 259.95it/s, lambda=2831.02]
52%|█████▏ | 26/50 [00:00<00:00, 259.95it/s, lambda=2831.02]
52%|█████▏ | 26/50 [00:00<00:00, 259.95it/s, lambda=2831.02]
52%|█████▏ | 26/50 [00:00<00:00, 259.95it/s, lambda=2831.02]
52%|█████▏ | 26/50 [00:00<00:00, 259.95it/s, lambda=2831.02]
52%|█████▏ | 26/50 [00:00<00:00, 259.95it/s, lambda=2831.02]
52%|█████▏ | 26/50 [00:00<00:00, 259.95it/s, lambda=2831.02]
52%|█████▏ | 26/50 [00:00<00:00, 259.95it/s, lambda=2831.02]
52%|█████▏ | 26/50 [00:00<00:00, 259.95it/s, lambda=2831.02]
52%|█████▏ | 26/50 [00:00<00:00, 259.95it/s, lambda=2831.02]
52%|█████▏ | 26/50 [00:00<00:00, 259.95it/s, lambda=2831.02]
52%|█████▏ | 26/50 [00:00<00:00, 259.95it/s, lambda=2831.02]
52%|█████▏ | 26/50 [00:00<00:00, 259.95it/s, lambda=2831.02]
52%|█████▏ | 26/50 [00:00<00:00, 259.95it/s, lambda=2831.02]
52%|█████▏ | 26/50 [00:00<00:00, 259.95it/s, lambda=2831.02]
52%|█████▏ | 26/50 [00:00<00:00, 259.95it/s, lambda=2831.02]
52%|█████▏ | 26/50 [00:00<00:00, 259.95it/s, lambda=2831.02]
52%|█████▏ | 26/50 [00:00<00:00, 259.95it/s, lambda=2831.02]
52%|█████▏ | 26/50 [00:00<00:00, 259.95it/s, lambda=2831.02]
52%|█████▏ | 26/50 [00:00<00:00, 259.95it/s, lambda=2831.02]
52%|█████▏ | 26/50 [00:00<00:00, 259.95it/s, lambda=2831.02]
52%|█████▏ | 26/50 [00:00<00:00, 259.95it/s, lambda=2831.02]
52%|█████▏ | 26/50 [00:00<00:00, 259.95it/s, lambda=2831.02]
52%|█████▏ | 26/50 [00:00<00:00, 259.95it/s, lambda=2831.02]
100%|██████████| 50/50 [00:00<00:00, 295.86it/s, lambda=2831.02]
Linear(in_features=2, out_features=1, bias=True)
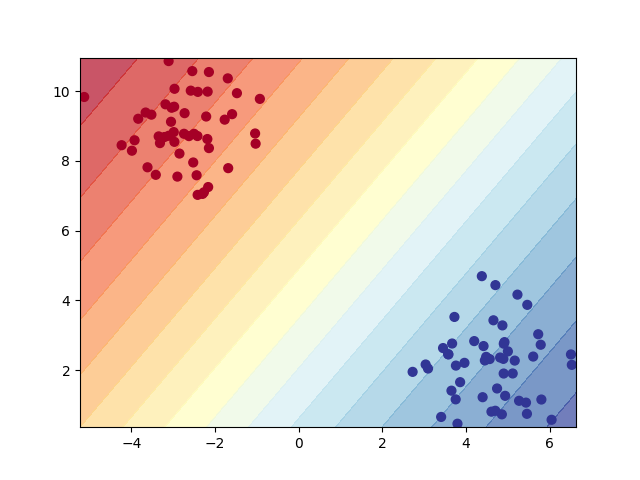
Fifth model: Results#
plot_decision_boundary(model5, X, y, n_levels=20)
Sixth model: Quadratic Hinge loss#
Same as last example, without the restriction mentioned: only the negative part of the margin is penalized by this loss.
Sixth model: Training#
model6 = train(dro_model, (X, y), epochs=50) # type: ignore
model6.eval() # type: ignore
0%| | 0/50 [00:00<?, ?it/s]
0%| | 0/50 [00:00<?, ?it/s, lambda=2801.97]
0%| | 0/50 [00:00<?, ?it/s, lambda=2801.97]
0%| | 0/50 [00:00<?, ?it/s, lambda=2801.97]
0%| | 0/50 [00:00<?, ?it/s, lambda=2801.97]
0%| | 0/50 [00:00<?, ?it/s, lambda=2801.97]
0%| | 0/50 [00:00<?, ?it/s, lambda=2801.97]
0%| | 0/50 [00:00<?, ?it/s, lambda=2801.97]
0%| | 0/50 [00:00<?, ?it/s, lambda=2801.97]
0%| | 0/50 [00:00<?, ?it/s, lambda=2801.97]
0%| | 0/50 [00:00<?, ?it/s, lambda=2801.97]
0%| | 0/50 [00:00<?, ?it/s, lambda=2801.97]
0%| | 0/50 [00:00<?, ?it/s, lambda=2801.97]
0%| | 0/50 [00:00<?, ?it/s, lambda=2801.97]
0%| | 0/50 [00:00<?, ?it/s, lambda=2801.97]
0%| | 0/50 [00:00<?, ?it/s, lambda=2801.97]
0%| | 0/50 [00:00<?, ?it/s, lambda=2801.97]
0%| | 0/50 [00:00<?, ?it/s, lambda=2801.97]
0%| | 0/50 [00:00<?, ?it/s, lambda=2801.97]
0%| | 0/50 [00:00<?, ?it/s, lambda=2801.97]
0%| | 0/50 [00:00<?, ?it/s, lambda=2801.97]
0%| | 0/50 [00:00<?, ?it/s, lambda=2801.97]
0%| | 0/50 [00:00<?, ?it/s, lambda=2801.97]
0%| | 0/50 [00:00<?, ?it/s, lambda=2801.97]
0%| | 0/50 [00:00<?, ?it/s, lambda=2801.97]
0%| | 0/50 [00:00<?, ?it/s, lambda=2801.97]
0%| | 0/50 [00:00<?, ?it/s, lambda=2801.97]
0%| | 0/50 [00:00<?, ?it/s, lambda=2801.97]
0%| | 0/50 [00:00<?, ?it/s, lambda=2801.97]
0%| | 0/50 [00:00<?, ?it/s, lambda=2801.97]
0%| | 0/50 [00:00<?, ?it/s, lambda=2801.97]
0%| | 0/50 [00:00<?, ?it/s, lambda=2801.97]
0%| | 0/50 [00:00<?, ?it/s, lambda=2801.97]
64%|██████▍ | 32/50 [00:00<00:00, 313.57it/s, lambda=2801.97]
64%|██████▍ | 32/50 [00:00<00:00, 313.57it/s, lambda=2801.97]
64%|██████▍ | 32/50 [00:00<00:00, 313.57it/s, lambda=2801.97]
64%|██████▍ | 32/50 [00:00<00:00, 313.57it/s, lambda=2801.97]
64%|██████▍ | 32/50 [00:00<00:00, 313.57it/s, lambda=2801.97]
64%|██████▍ | 32/50 [00:00<00:00, 313.57it/s, lambda=2801.97]
64%|██████▍ | 32/50 [00:00<00:00, 313.57it/s, lambda=2801.97]
64%|██████▍ | 32/50 [00:00<00:00, 313.57it/s, lambda=2801.97]
64%|██████▍ | 32/50 [00:00<00:00, 313.57it/s, lambda=2801.97]
64%|██████▍ | 32/50 [00:00<00:00, 313.57it/s, lambda=2801.97]
64%|██████▍ | 32/50 [00:00<00:00, 313.57it/s, lambda=2801.97]
64%|██████▍ | 32/50 [00:00<00:00, 313.57it/s, lambda=2801.97]
64%|██████▍ | 32/50 [00:00<00:00, 313.57it/s, lambda=2801.97]
64%|██████▍ | 32/50 [00:00<00:00, 313.57it/s, lambda=2801.97]
64%|██████▍ | 32/50 [00:00<00:00, 313.57it/s, lambda=2801.97]
64%|██████▍ | 32/50 [00:00<00:00, 313.57it/s, lambda=2801.97]
64%|██████▍ | 32/50 [00:00<00:00, 313.57it/s, lambda=2801.97]
64%|██████▍ | 32/50 [00:00<00:00, 313.57it/s, lambda=2801.97]
64%|██████▍ | 32/50 [00:00<00:00, 313.57it/s, lambda=2801.97]
100%|██████████| 50/50 [00:00<00:00, 327.91it/s, lambda=2801.97]
Linear(in_features=2, out_features=1, bias=True)
Sixth model: Results#
plot_decision_boundary(model6, X, y, n_levels=20)
Bonus: Exponential Loss#
From a theoretical perspective, this loss is interesting for its lack of usual properties for the WDRO framework: it is not Lipschitz, and does not validate a 2nd order growth condition. It is not strongly convex either and not bounded.
Bonus model: Training#
model7 = train(dro_model, (X, y), epochs=50) # type: ignore
model7.eval() # type: ignore
0%| | 0/50 [00:00<?, ?it/s]
0%| | 0/50 [00:00<?, ?it/s, lambda=-0.00]
0%| | 0/50 [00:00<?, ?it/s, lambda=-0.00]
0%| | 0/50 [00:00<?, ?it/s, lambda=-0.00]
0%| | 0/50 [00:00<?, ?it/s, lambda=-0.00]
8%|▊ | 4/50 [00:00<00:01, 32.55it/s, lambda=-0.00]
8%|▊ | 4/50 [00:00<00:01, 32.55it/s, lambda=-0.00]
8%|▊ | 4/50 [00:00<00:01, 32.55it/s, lambda=-0.00]
8%|▊ | 4/50 [00:00<00:01, 32.55it/s, lambda=-0.00]
8%|▊ | 4/50 [00:00<00:01, 32.55it/s, lambda=-0.00]
16%|█▌ | 8/50 [00:00<00:01, 32.06it/s, lambda=-0.00]
16%|█▌ | 8/50 [00:00<00:01, 32.06it/s, lambda=-0.00]
16%|█▌ | 8/50 [00:00<00:01, 32.06it/s, lambda=-0.00]
16%|█▌ | 8/50 [00:00<00:01, 32.06it/s, lambda=-0.00]
16%|█▌ | 8/50 [00:00<00:01, 32.06it/s, lambda=-0.00]
24%|██▍ | 12/50 [00:00<00:01, 31.48it/s, lambda=-0.00]
24%|██▍ | 12/50 [00:00<00:01, 31.48it/s, lambda=-0.00]
24%|██▍ | 12/50 [00:00<00:01, 31.48it/s, lambda=-0.00]
24%|██▍ | 12/50 [00:00<00:01, 31.48it/s, lambda=-0.00]
24%|██▍ | 12/50 [00:00<00:01, 31.48it/s, lambda=-0.00]
32%|███▏ | 16/50 [00:00<00:01, 30.88it/s, lambda=-0.00]
32%|███▏ | 16/50 [00:00<00:01, 30.88it/s, lambda=-0.00]
32%|███▏ | 16/50 [00:00<00:01, 30.88it/s, lambda=-0.00]
32%|███▏ | 16/50 [00:00<00:01, 30.88it/s, lambda=-0.00]
32%|███▏ | 16/50 [00:00<00:01, 30.88it/s, lambda=-0.00]
40%|████ | 20/50 [00:00<00:00, 30.28it/s, lambda=-0.00]
40%|████ | 20/50 [00:00<00:00, 30.28it/s, lambda=-0.00]
40%|████ | 20/50 [00:00<00:00, 30.28it/s, lambda=-0.00]
40%|████ | 20/50 [00:00<00:00, 30.28it/s, lambda=-0.00]
40%|████ | 20/50 [00:00<00:00, 30.28it/s, lambda=-0.00]
48%|████▊ | 24/50 [00:00<00:00, 29.71it/s, lambda=-0.00]
48%|████▊ | 24/50 [00:00<00:00, 29.71it/s, lambda=-0.00]
48%|████▊ | 24/50 [00:00<00:00, 29.71it/s, lambda=-0.00]
48%|████▊ | 24/50 [00:00<00:00, 29.71it/s, lambda=-0.00]
54%|█████▍ | 27/50 [00:00<00:00, 29.24it/s, lambda=-0.00]
54%|█████▍ | 27/50 [00:00<00:00, 29.24it/s, lambda=-0.00]
54%|█████▍ | 27/50 [00:00<00:00, 29.24it/s, lambda=-0.00]
54%|█████▍ | 27/50 [00:01<00:00, 29.24it/s, lambda=-0.00]
60%|██████ | 30/50 [00:01<00:00, 28.74it/s, lambda=-0.00]
60%|██████ | 30/50 [00:01<00:00, 28.74it/s, lambda=-0.00]
60%|██████ | 30/50 [00:01<00:00, 28.74it/s, lambda=-0.00]
60%|██████ | 30/50 [00:01<00:00, 28.74it/s, lambda=-0.00]
66%|██████▌ | 33/50 [00:01<00:00, 28.23it/s, lambda=-0.00]
66%|██████▌ | 33/50 [00:01<00:00, 28.23it/s, lambda=-0.00]
66%|██████▌ | 33/50 [00:01<00:00, 28.23it/s, lambda=-0.00]
66%|██████▌ | 33/50 [00:01<00:00, 28.23it/s, lambda=-0.00]
72%|███████▏ | 36/50 [00:01<00:00, 27.73it/s, lambda=-0.00]
72%|███████▏ | 36/50 [00:01<00:00, 27.73it/s, lambda=-0.00]
72%|███████▏ | 36/50 [00:01<00:00, 27.73it/s, lambda=-0.00]
72%|███████▏ | 36/50 [00:01<00:00, 27.73it/s, lambda=-0.00]
78%|███████▊ | 39/50 [00:01<00:00, 27.23it/s, lambda=-0.00]
78%|███████▊ | 39/50 [00:01<00:00, 27.23it/s, lambda=-0.00]
78%|███████▊ | 39/50 [00:01<00:00, 27.23it/s, lambda=-0.00]
78%|███████▊ | 39/50 [00:01<00:00, 27.23it/s, lambda=-0.00]
84%|████████▍ | 42/50 [00:01<00:00, 26.73it/s, lambda=-0.00]
84%|████████▍ | 42/50 [00:01<00:00, 26.73it/s, lambda=-0.00]
84%|████████▍ | 42/50 [00:01<00:00, 26.73it/s, lambda=-0.00]
84%|████████▍ | 42/50 [00:01<00:00, 26.73it/s, lambda=-0.00]
90%|█████████ | 45/50 [00:01<00:00, 26.28it/s, lambda=-0.00]
90%|█████████ | 45/50 [00:01<00:00, 26.28it/s, lambda=-0.00]
90%|█████████ | 45/50 [00:01<00:00, 26.28it/s, lambda=-0.00]
90%|█████████ | 45/50 [00:01<00:00, 26.28it/s, lambda=-0.00]
96%|█████████▌| 48/50 [00:01<00:00, 25.84it/s, lambda=-0.00]
96%|█████████▌| 48/50 [00:01<00:00, 25.84it/s, lambda=-0.00]
96%|█████████▌| 48/50 [00:01<00:00, 25.84it/s, lambda=-0.00]
100%|██████████| 50/50 [00:01<00:00, 28.06it/s, lambda=-0.00]
Linear(in_features=2, out_features=1, bias=True)
Bonus model: Results#
plot_decision_boundary(model7, X, y, n_levels=20)
References#
Total running time of the script: (0 minutes 9.104 seconds)