Note
Go to the end to download the full example code.
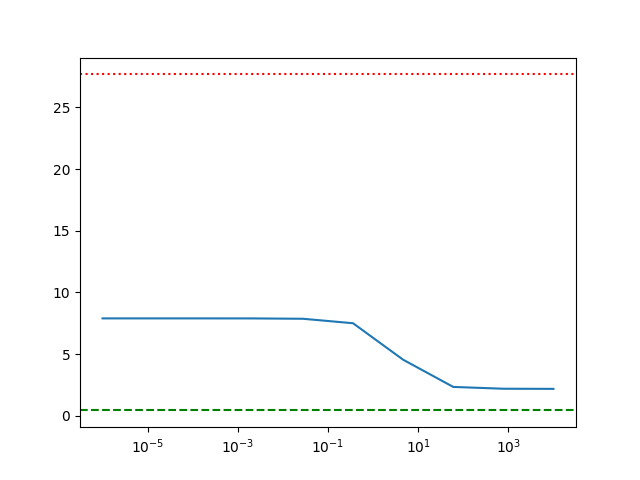
Study the relationship between ERM, WDRO, and SkWDRO#
This example illustrates the use of the skwdro.linear_models.LogisticRegression class on datasets that are shifted at test time.
It showcases the approximation properties of the SkWDRO estimator with respect to the non-regularized Wasserstein-distributionally robusst estimator (WDRO), and the Empirical Risk estimator (ERM).
This is possible because the WDRO estimator is available through a “closed form”, see (Shafieezadeh-Esfahani-Kuhn, 2015)
import numpy as np
from sklearn.datasets import make_blobs
from skwdro.torch import robustify
from sklearn.linear_model import LogisticRegression
from scipy.optimize import line_search
from skwdro.linear_models._logistic_regression import BiDiffSoftMarginLoss
import torch as pt
import torch.nn as nn
import matplotlib.pyplot as plt
from tqdm import tqdm
N_LAMBDA_OPTIM_STEPS = 100
Here is the forward pass for a given lambda, at fixed parameters
@pt.no_grad()
def fwd(model, l, X, y):
model._lam = pt.nn.Parameter(pt.tensor(l))
return model(X, y).detach().numpy()
Then pick one of the two following functions to find lambda: * either pick a satisfying multiplier with the strong-Wolfe-Armijo criterion, * or optimize it by hand with vanilla gradient descent.
def line_optim_Wolfe(
model,
X: pt.Tensor, y: pt.Tensor,
old_loss: pt.Tensor
) -> tuple[float, float]:
"""
"either pick a satisfying multiplier with the strong-Wolfe-Armijo criterion" option
"""
def f(l):
return fwd(model, l, X, y)
def f_prime(l):
model._lam = pt.nn.Parameter(pt.tensor(l))
loss = model(X, y)
loss.backward()
assert model._lam.grad is not None
return model._lam.grad.detach().numpy()
def extra_condition(a, l, f, g):
del a, f, g
return l >= 0
old_l = model._lam.detach().numpy()
g = model._lam.grad.detach().numpy()
alpha, *misc = line_search(
f, f_prime,
old_l,
pk=-g,
gfk=g,
old_fval=old_loss.detach().numpy(),
c1=0.01, c2=0.999,
extra_condition=extra_condition,
maxiter=N_LAMBDA_OPTIM_STEPS
)
if alpha is None:
if g >= 0.:
return np.inf, np.inf
else:
return 0., f(0.)
else:
assert misc[2] is not None
return (old_l - alpha * g).item(), misc[2]
def line_optim(
model,
X: pt.Tensor, y: pt.Tensor,
old_loss: pt.Tensor
) -> tuple[float, float]:
"""
"or optimize it by hand with vanilla gradient descent" option
"""
def f_prime(l):
model._lam = pt.nn.Parameter(l)
loss = model(X, y)
loss.backward()
assert model._lam.grad is not None
return loss, model._lam.grad
def extra_condition(a, l, f, g):
del a, f, g
return l >= 0
lam = pt.zeros_like(model._lam.detach())
f = past_f = old_loss
s = 0
for iter in range(N_LAMBDA_OPTIM_STEPS):
f, g = f_prime(lam)
lam -= 0.01 * g
if not extra_condition(None, lam, f, g):
lam *= 0.
if pt.abs(f - past_f) < 1e-5:
s += 1
if s == 10:
break
past_f = f
return lam.detach().cpu().item(), f.detach().cpu().item()
Setup#
We build a custom 2-blobs dataset.
n = 50 # Total number of samples
sdevs = (1, 5) # train on this, plan to test on wider variance or different means
# Fix centers for blobs dataset
pos = 4
centers = [np.array([-pos,-pos]), np.array([pos,pos])]
# Create datasets with variance that is shifted at test time
X_train, y_train = make_blobs(n_samples=n, centers=centers, cluster_std=sdevs) # type: ignore
WDRO classifiers#
The exact 1-WDRO loss for the linear classifier is given by (Shafieezadeh-Esfahani-Kuhn, 2015):
- ..math::
frac{1}{N}sum_{i=1}^NL(xi_i)+rho|theta|_*
In this case we pick the two-norm for our euclidean space.
rho = 2*4**2
# Enthropic regularization: test various ones
regs = np.logspace(
-6, 4,
base=10,
num=10 # try 100 at home
)
# Cost:
# t: torch backend
# NC: norm cost that does not take labels into account
# 1 2 : 2-norm (not squared!)
cost = f"t-NC-1-2"
erm_model = LogisticRegression(fit_intercept=False).fit(X_train, y_train)
erm_params = (erm_model.coef_, erm_model.intercept_)
# WDRO classifier
X_train, y_train = pt.from_numpy(X_train), pt.from_numpy(y_train).double().unsqueeze(-1)
loss = BiDiffSoftMarginLoss(reduction='none')
linear_model = nn.Linear(2, 1, bias=False)
linear_model.weight = pt.nn.Parameter(pt.from_numpy(erm_params[0]))
# linear_model.bias = pt.nn.Parameter(pt.from_numpy(erm_params[1]))
linear_model = linear_model.to(X_train)
wdro_loss = loss(
linear_model(X_train), y_train
).mean() + rho * pt.linalg.norm(linear_model.weight.flatten())
classifiers = [
robustify(
loss,
linear_model,
pt.tensor(rho),
X_train,
y_train,
cost_spec=cost,
epsilon=eps,
n_samples=10 # Try 1000 at home
) for eps in regs
]
skwdro_losses = []
for c in tqdm(classifiers):
c.freeze()
c._lam.requires_grad_()
loss_before = c(X_train, y_train)
loss_before.backward()
lam, skloss = line_optim(c, X_train, y_train, loss_before)
skwdro_losses.append(skloss)
0%| | 0/10 [00:00<?, ?it/s]
70%|███████ | 7/10 [00:00<00:00, 63.95it/s]
100%|██████████| 10/10 [00:00<00:00, 68.80it/s]
Make plot#
fig, ax = plt.subplots()
# Save your plots if you wish to
# np.savez_compressed("./epsiloncurve.npz", l=skwdro_losses, e=regs)
ax.semilogx(regs, np.array(skwdro_losses), label='$\\varepsilon$-robust loss')
ax.axhline(wdro_loss.detach().item(), color='r', label='WDRO', linestyle='dotted')
ax.axhline(loss(linear_model(X_train), y_train).mean().detach().item(), color='g', label='ERM', linestyle='--')
plt.show()
Total running time of the script: (0 minutes 0.209 seconds)