skwdro.linear_models.LogisticRegression
- class skwdro.linear_models.LogisticRegression(rho: float = 0.01, l2_reg: float = 0.0, fit_intercept: bool = True, cost: str = 't-NLC-2-2', solver='entropic_torch', solver_reg: float | None = None, sampler_reg: float | None = None, n_zeta_samples: int = 10, random_state: int = 0, opt_cond: ~skwdro.solvers.optim_cond.OptCondTorch | None = <skwdro.solvers.optim_cond.OptCondTorch object>)[source]
A Wasserstein Distributionally Robust logistic regression classifier.
The cost function is XXX
Uncertainty is XXX
- Parameters:
- rho: float, default=1e-2
Robustness radius
- l2_reg: float, default=None
l2 regularization
- fit_intercept: boolean, default=True
Determines if an intercept is fit or not
- cost: str, default=”n-NC-1-2”
Tiret-separated code to define the transport cost: “<engine>-<cost id>-<k-norm type>-<power>” for
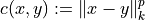
- solver: str, default=’entropic_torch’
Solver to be used: ‘entropic’, ‘entropic_torch’ (_pre or _post) or ‘dedicated’
- solver_reg: float, default=1e-2
regularization value for the entropic solver
- n_zeta_samples: int, default=10
number of adversarial samples to draw
- opt_cond: Optional[OptCondTorch]
optimality condition, see
OptCondTorch
- Attributes:
- coef_array, shape (n_features,)
parameter vector (
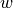 in the cost function formula)
in the cost function formula)- intercept_float
constant term in decision function.
Examples
>>> import numpy as np >>> from skwdro.linear_models import LogisticRegression >>> from sklearn.datasets import make_blobs >>> from sklearn.model_selection import train_test_split >>> X, y = make_blobs(n_samples=100, centers=2, n_features=2, random_state=0) >>> y = np.sign(y-0.5) >>> X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42) >>> estimator = LogisticRegression() >>> estimator.fit(X_train,y_train) LogisticRegression() >>> estimator.predict(X_test) array([-1., -1., -1., 1., -1., 1., 1., -1., -1., 1., 1., 1., -1., 1., 1., 1., 1., 1., -1., -1., -1., 1., 1., -1., -1., 1., -1., 1., 1., 1., 1., 1., -1.]) >>> estimator.score(X_test,y_test) 0.9393939393939394